подробное описание создания, схемы и чертежи + (фото инструкция)
На сегодняшний период времени увеличивающие или уменьшающие трансформаторы применяются для изменения напряжения. Данное устройство является машиной с высоким уровнем КПД и используется в большинстве сферах техники. Нередко людей интересует, как создать каркас и другие части трансформатора собственноручно.
Чтобы выполнить подобную задачу не обойтись без специальных умений. Помимо этого важно быть в курсе всего технологического процесса.
Краткое содержимое статьи:
Создаём трансформатор
При необходимости сделать данный прибор, важно ответить на ряд вопросов, в том числе:
- Какое непосредственно напряжение должен он пропускать?
- На какой именно частоте планируется запустить в работу устройство?
- Для каких целей требуется аппарат: для снижения или увеличения тока?
Какую мощь будет иметь?
Как только вы сможете ответить на каждый из перечисленных вопросов, приобретайте требуемые материалы.
Трансформатор собственноручно требует намотку. В этих целях следует создать станок, изготовление которого осуществляется из доски длиною сорок сантиметров и шириною десять сантиметров. На доску необходимо прикрепить несколько брусков, посредством шурупов.
Расстояние, имеющееся между брусками не должно быть менее чем тридцать сантиметров. Затем следует просверлить отверстия восемь миллиметров диаметром. В созданные отверстия нужно вставить специальные пруты для катушки аппарата.
С одной из сторон следует создать резьбу. Закрутив обустроенную шайбу, вы получите его ручку. Габариты станка для намотки можно выбрать на собственное усмотрение. Прежде всего, правильный выбор напрямую зависит от габарита сердечника. При кольцевидной его форме намотка создаётся вручную.
Согласно схеме трансформаторного устройства, аппарат может быть оснащён разнообразным числом витков. Требуемое их количество рассчитывается, ориентируясь на мощность. К примеру, при необходимости создания прибора до 220 вольт, мощность должна достигать не менее 150 ватт.
Форма магнитного провода должна быть о-образной. Можно обустроить его из бу телевизора. При этом сечение определяется посредством определённой формулы.
Обустройство катушечного корпуса
Корпус делают из качественной картонной бумаги. Внутренняя его сторона слега больше в сравнении со стержневой частью сердечника. При применении о-образного сердечника потребуется несколько катушек. При сердечнике ш-образном достаточно использовать всего одну катушку.
Применяя сердечник круглой формы, его следует обмотать, применяя изоляцию. Затем можно осуществлять проводную намотку. Как только вы завершите с обмоткой первичной, её следует закрыть несколькими изоляционными слоями.
После этого нужно накрутить очередной слой. Концы имеющихся обмоток выводятся на наружную сторону.
При применении магнитного провода корпус трансформатора собирается пошагово:
- Осуществляется выкраивание определённого размера гильзы с требуемыми отворотами.
- Создаются картонные щёчки.
- Основная часть катушки сворачивается в специальную коробочку.
- На гильзы надеваются щёчки.
Создание обмоток для увеличивающего трансформатора
Следует надеть катушку на брусок из натурального массива. В нём необходимо просверлить специальное отверстие для прутка намоточного.
К одному из серьёзных этапов относится подключение тока. Деталь вставляется внутрь станка и можно производить обмотку:
- Сверху катушки наматывается лакоткань в несколько слоёв.
- Конец имеющегося провода закрепляется на обустроенной щёчке, после чего можно приступать к вращению ручку.
- Витки укладываются максимально плотно.

- После обмотки следует обрезать провод для последующего закрепления сверху щёчки возле первого.
- На имеющиеся выводы необходимо закрепить трубку изоляционную.

Сборка трансформатора увеличивающего
При необходимости узнать, как создать собственноручно трансформатор, воспользуйтесь инструкцией. Для сборки повышающего устройства важно разобрать полностью сердечник. При применении отдельно размещённых пластин, важно определиться с пакетной толщиной, рассчитать листы.
В случае если в процессе включения аппарата будет издаваться шум, то необходимо закрепить имеющийся крепёж максимально плотно. Затем следует проверить прибор на работоспособность. В этих целях он подключается к сети, после чего должно высветиться напряжение, составляющее 12В.
Немаловажно знать, что в процессе включения аппарата, важно оставить его в работающем состоянии на пару часов. При этом трансформатор должен не перегреваться.

Инструменты
Чтобы изготовить трансформатор собственноручно, следует взять инструменты, а также определённые материалы:
- Лакоткань.
- Сердечник, для которого вполне подходит телевизор бывший в использовании.
- Плотная картонная бумага.
- Доски, а также бруски из природной древесины.
- Прут из стали.
- Пила, специальный клей.
Сделать собственными руками трансформатор, как на фото, совершенно не проблематично. Если требуется изготовление трансформатора, предназначенного для лампочек галогенных, то вполне можно использовать тоже перечисленные выше инструменты.
Не забывайте, что очень важно придерживаться технологического процесса намотки. При точном соблюдении важных правил, аппарат прослужит вам ни одно десятилетие. Данных материалов, а также инструментов вам будет вполне достаточно для собственноручного создания качественного и практичного в применении трансформатора.
На основе подобной самоделки можно сформировать трансформатор для подзарядки машинного аккумулятора, либо создать повышающий прибор для источника питания лабораторного, выжигатель по древесине, либо другое устройство, которое удовлетворит нужды мастера по дому.
Фото трансформаторов своими руками
Трансформатор своими руками: инструкция + фото
Принцип действия трансформатора
От устройства трансформатора перейдём к принципу его работы. Для этого рассмотрим трансформатор изображённый на рисунке ниже.
Данный трансформатор состоит из двух катушек (обмоток) I и II, находящихся на стержневом магнитопроводе. К катушке I подводится переменное напряжение u1; это катушка называется первичной обмоткой. На выводах катушки II, называемой вторичной обмоткой, формируется напряжение u2, которое передается приёмникам электрической энергии.
К катушке I подводится переменное напряжение u1; это катушка называется первичной обмоткой. На выводах катушки II, называемой вторичной обмоткой, формируется напряжение u2, которое передается приёмникам электрической энергии.
Работа трансформатора заключается в следующем. При протекании переменного тока i1 в первичной обмотке I создаётся магнитное поле, магнитный поток, которого пронизывает не только создавшую его обмотку (магнитный поток Ф1), но и частично вторичную обмотку (магнитный поток Ф). То есть обмотки трансформатора являются магнитно связанными, при этом степень связи зависит от взаимного расположения обмоток: чем дальше обмотки друг от друга, тем меньше магнитная связь между ними и меньше магнитный поток Ф.
Так как через первичную обмотку протекает переменный ток, то и создаваемый им магнитный поток непрерывно изменяет свою величину и свое направление. Согласно закону электромагнитной индукции, при изменении пронизывающего катушку магнитного потока, в катушке индуцируется переменная электродвижущая сила. Таким образом, в первичной обмотке индуцируется электродвижущая сила самоиндукции, а во вторичной обмотке – электродвижущая сила взаимноиндукции.
Таким образом, в первичной обмотке индуцируется электродвижущая сила самоиндукции, а во вторичной обмотке – электродвижущая сила взаимноиндукции.
Если присоединить концы вторичной обмотки к приемнику электрической энергии (нагрузке), то через неё потечёт ток i2. В тоже время в первичную обмотку будет поступать ток i1 от источника энергии (генератора). Таким образом энергия от первичной обмотки во вторичную будет передаваться при помощи переменного магнитного потока Ф.
На рисунке видно, что часть магнитного потока первичной Ф1 и вторичной Ф2 обмотки не замыкается через магнитопровод. Они не участвуют в передаче энергии, а образуют так называемое магнитное поле рассеяния.
Одной из задач проектирования трансформаторов является сведение магнитного потока рассеяния к минимуму.
Трансформатор тока
Кроме стандартного типа трансформаторов напряжения существует особый вид, называемый трансформатором тока. Основное его назначение — изменять значение тока относительно своего входа. Другое название такого вида устройства — токовый.
Другое название такого вида устройства — токовый.
Токовое устройство по виду ничем не отличается от трансформатора напряжения, его отличия — в подключении и количестве витков в обмотке. Первичка выполняется с помощью одного или пары витков. Эти витки пропускаются через тороидальный магнитопровод, и именно через них измеряется ток. Токовые устройства выполняются не только тороидального типа, но и могут быть выполнены и на других видах сердечниках. Главным условием является то, чтобы измеряемый провод совершил полный виток.
Вторичная обмотка при таком исполнении шунтируется низкоомным сопротивлением. При этом величина напряжения на этой обмотке не должна быть большого значения, так как во время прохождения наибольших токов сердечник будет находиться в режиме насыщения.
В некоторых случаях измерения проводятся на нескольких проводниках которые пропущены через тор. Тогда величина тока будет пропорциональна силе суммы токов.
Как изготовить самостоятельно
Понижающий трансформатор можно выполнить как отдельное устройство либо расположить в блоке питания техники. По сути, это радиоэлектронный элемент и его под силу смастерить своими руками.
Сначала стоит подготовить инструменты и материал, произвести предварительный расчет. Для работы потребуется:
- ленточная изоляция высокого качества;
- сердечник, снятый со старого телевизора;
- провода с эмалевой изоляцией;
- простой станок для намотки, например, из доски (ширина – 10 см, длина – 40 см).
Пошаговые действия:
- Изготовить каркас, вырезав из картона внутреннюю часть, немного большую в отличие от стержня сердечника. Если используется сердечник в виде буквы “О”, то потребуется 2 катушки. При сердечнике буквой “Ш” хватит одной катушки.
- На круглый сердечник предварительно намотать изоляцию в 3 слоя после первичной обмотки.
- Накрутить второй слой с и выведением наружу концов обмотки. Вторичная, равно как и первичная обмотка, прокладываются в идентичном направлении. Главное, не забывать выводить провода.
- Вставить железные полоски в готовую катушку, обогнуть ими каркас с одной стороны, соединить внизу. Оставить между каркасом и сердечником воздушный зазор.
- Сделать основание для трансформатора. На дощечку (толщина 5 см) прикрепить металлическими скобами 2 бруска (50х50 см) на расстоянии в 30 см друг от друга. Согнуть скобы так, чтобы огибали нижнюю часть сердечника.
- Вывести на каркас концы обмоток, прикрепить к контактам.

На каждый Вольт должно прийтись по 10 витков. Рассчитать их нужное количество несложно. Сердечник можно вынуть из ненужного трансформатора любого типа или изготовить из жести. Подойдет консервная банка, из которой вырезается 80 полосок в длину 30 см, ширину – 2 см от. Отжигаются полоски их в печи, остужаются, очищаются от окалины и покрываются лаком. Можно с одной стороны оклеить тонкой бумагой.
Можно с одной стороны оклеить тонкой бумагой.
Заметка! Все разметки и линии нельзя делать графитом.
Расчет конструкции производится по формуле P = U * I,. Из нее исчисляется мощность, которая выдержит вторичную обмотку.
Как организуется внеочередная проверка знаний?
Организует внеочередную проверку знаний:
- служба ОТ;
- непосредственный руководитель работ;
- инспектор ГИТ или другой проверяющий;
- специализированный центр по договору с компанией, сотрудники которой будут экзаменоваться. Нужно учитывать, что в центре можно проверять знания только тех сотрудников, которые там обучались. Например, по Положению 1/29 нельзя провести обучение силами предприятия, а на проверку знаний придти в специализированный центр.
Обучение по охране труда в специализированном центре имеет преимущество – в их комиссии по проверке знаний включаются представители надзорных органов. Поэтому к таким проверкам все готовятся особенно тщательно. Во время проверки состояния безопасности на предприятии удостоверение с подписью инспектора – дополнительный «+». В собственные комиссии предприятий их можно не включать – здесь достаточно руководителей и главных специалистов подразделений, специалистов по ОТ, представителей трудящихся. Минимальная численность комиссии – 3 человека. Включая должностных лиц в комиссию, нужно понимать сферу их деятельности и ответственности. Соответственно комплектуются группы. Например, включать в одну группу обучающихся грузчиков и электрослесарей нецелесообразно.
В собственные комиссии предприятий их можно не включать – здесь достаточно руководителей и главных специалистов подразделений, специалистов по ОТ, представителей трудящихся. Минимальная численность комиссии – 3 человека. Включая должностных лиц в комиссию, нужно понимать сферу их деятельности и ответственности. Соответственно комплектуются группы. Например, включать в одну группу обучающихся грузчиков и электрослесарей нецелесообразно.
Перед экзаменом трудящимся можно и нужно раздавать билеты, списки контрольных вопросов, чтобы они могли лучше подготовиться к экзамену и не тратить время на изучение ненужного материала. А вот ответы на билеты раздавать нельзя. Эту информацию трудящиеся должны получить во время обучения. Можно проводить пробные проверки знаний, если есть время. Главная ценность такой подготовки – возможность проработать ошибочные ответы, детально разъяснить неправильно понятые положения
Нужно обращать внимание, чтобы трудящиеся не только знали требования правил, инструкций и норм, но и четко понимали, как реализовать их на практике. В этом помогает моделирование ситуаций в аудитории или при помощи автоматизированных обучающих комплексов
В этом помогает моделирование ситуаций в аудитории или при помощи автоматизированных обучающих комплексов
Как будет проводиться проверка, какой материал будет проверяться, решает ее инициатор. Поэтому, когда во внеплановую проверку вовлекается большое количество трудящихся, а срок плановой проверки знаний уже близок, можно совместить 2 вида обучения. При этом все вопросы можно проверить в рамках 1 экзамена с заполнением соответствующей документации. Называть мероприятие лучше плановой проверкой, потому что проведение внеплановой проверки ее не отменяет. Чтобы отметить расширенный формат мероприятия, можно назвать его, например «расширенной плановой проверкой знаний».
Материал, по которому проводилась внеплановая проверка знаний, включается в программы последующих обучений и инструктажей. Соответственно, устаревшие нормы из них убираются. Внесенные изменения утверждаются приказом или распоряжением.
Поскольку оперативно корректировать периодичность проверки знаний по охране труда в крупных организациях – дело не одного дня, при вводе новых нормативных документов государство дает специалистам по обучению время на адаптацию учебных программ. Например, документ утверждается и выкладывается в общий доступ в январе, а вступает в силу только в июле. За это время можно успеть организовать обучение трудящихся и избежать нарушений. Возможен другой путь, как это было сделано в ФЗ о спецоценке условий труда – документ был утвержден и сразу же введен в действие, но чтобы перестроиться под требования его положений, компаниям был дан определенный срок.
Например, документ утверждается и выкладывается в общий доступ в январе, а вступает в силу только в июле. За это время можно успеть организовать обучение трудящихся и избежать нарушений. Возможен другой путь, как это было сделано в ФЗ о спецоценке условий труда – документ был утвержден и сразу же введен в действие, но чтобы перестроиться под требования его положений, компаниям был дан определенный срок.
Как повысить силу тока в цепи?
Бывают ситуации, когда требуется повысить I, который протекает в цепи, но при этом важно понимать, что нужно принять меры по защите электроприборов, сделать это можно с помощью специальных устройств. Рассмотрим, как повысить силу тока с помощью простых приборов
Рассмотрим, как повысить силу тока с помощью простых приборов.
Для выполнения работы потребуется амперметр.
По закону Ома ток равен напряжению (U), деленному на сопротивление (R). Простейший путь повышения силы I, который напрашивается сам собой — увеличение напряжения, которое подается на вход цепи, или же снижение сопротивления. При этом I будет увеличиваться прямо пропорционально U.
При этом I будет увеличиваться прямо пропорционально U.
К примеру, при подключении цепи в 20 Ом к источнику питания c U = 3 Вольта, величина тока будет равна 0,15 А.
Если добавить к цепи еще один источник питания на 3В, общую величину U удается повысить до 6 Вольт. Соответственно, ток также вырастет в два раза и достигнет предела в 0,3 Ампера.
Подключение источников питания должно осуществляться последовательно, то есть плюс одного элемента подключается к минусу первого.
Для получения требуемого напряжения достаточно соединить в одну группу несколько источников питания.
В быту источники постоянного U, объединенные в одну группу, называются батарейками.
Несмотря на очевидность формулы, практические результаты могут отличаться от теоретических расчетов, что связано с дополнительными факторами — нагревом проводника, его сечением, применяемым материалом и так далее.
В итоге R меняется в сторону увеличения, что приводит и к снижению силы I.
Повышение нагрузки в электрической цепи может стать причиной перегрева проводников, перегорания или даже пожара.
Вот почему важно быть внимательным при эксплуатации приборов и учитывать их мощность при выборе сечения. Величину I можно повысить и другим путем, уменьшив сопротивление
К примеру, если напряжение на входе равно 3 Вольта, а R 30 Ом, то по цепи проходит ток, равный 0,1 Ампер
Величину I можно повысить и другим путем, уменьшив сопротивление. К примеру, если напряжение на входе равно 3 Вольта, а R 30 Ом, то по цепи проходит ток, равный 0,1 Ампер.
Если уменьшить сопротивление до 15 Ом, сила тока, наоборот, возрастет в два раза и достигнет 0,2 Ампер. Нагрузка снижается почти к нулю при КЗ возле источника питания, в этом случае I возрастают до максимально возможной величины (с учетом мощности изделия).
Дополнительное снизить сопротивление можно путем охлаждения провода. Такой эффект сверхпроводимости давно известен и активно применяется на практике.
Чтобы повысить силу тока в цепи часто применяются электронные приборы, например, трансформаторы тока (как в сварочниках). Сила переменного I в этом случае возрастает при снижении частоты.
Если в цепи переменного тока имеется активное сопротивление, I увеличивается при росте емкости конденсатора и снижении индуктивности катушки.
В ситуации, когда нагрузка имеет чисто емкостной характер, сила тока возрастает при повышении частоты. Если же в цепь входят катушки индуктивности, сила I будет увеличиваться одновременно со снижением частоты.
Чтобы повысить силу тока, можно ориентироваться на еще одну формулу, которая выглядит следующим образом:
I = U*S/(ρ*l). Здесь нам неизвестно только три параметра:
- S — сечение провода;
- l — его длина;
- ρ — удельное электрическое сопротивление проводника.
Чтобы повысить ток, соберите цепочку, в которой будет источник тока, потребитель и провода.
Роль источника тока будет выполнять выпрямитель, позволяющий регулировать ЭДС.
Подключайте цепочку к источнику, а тестер к потребителю (предварительно настройте прибор на измерение силы тока). Повышайте ЭДС и контролируйте показатели на приборе.
Как отмечалось выше, при росте U удается повысить и ток. Аналогичный эксперимент можно сделать и для сопротивления.
Для этого выясните, из какого материала сделаны провода и установите изделия, имеющие меньшее удельное сопротивление. Если найти другие проводники не удается, укоротите те, что уже установлены.
Еще один путь — увеличение поперечного сечения, для чего параллельно установленным проводам стоит смонтировать аналогичные проводники. В этом случае возрастает площадь сечения провода и увеличивается ток.
Если же укоротить проводники, интересующий нас параметр (I) возрастет. При желании варианты увеличения силы тока разрешается комбинировать. Например, если на 50% укоротить проводники в цепи, а U поднять на 300%, то сила I возрастет в 9 раз.
Выбор инструментов
Чтобы сделать намотку для трансформатора максимально правильно, следует приобрести нужные для работы приспособления:
Часто для подобных целей применяют колодку из натурального массива, в которой делают отверстие для необходимой оси, а также подгоняют под требуемые каркасные размеры. Легче сделать всё это посредством дрели.
Её следует укрепить таким образом, чтобы размещение было параллельно настольной поверхности, в патрон вставляется непосредственно прут, на который заблаговременно нужно надеть колодку с трансформаторным каркасом. Желательно выбрать прут, который имеет резьбу. В данном варианте колодка просто фиксируется посредством гаек.
Также к элементу, без которого невозможно составить схему для собственноручного создания трансформатора, считается приспособление для размотки. Как правило, подобного типа устройства функционируют, как и приспособления для размотки, разница состоит в том, что в этом варианте можно не использовать ручку вращения.
Чтобы определиться с количеством требуемых витков, потребуется специальный прибор, к примеру, водяной счётчик. Для бесперебойной работы прибора необходимо соединить его со станком наматывающего типа посредством гибкого валика. При отсутствии данного приспособления можно подсчитать витки в уме.
Принцип функционирования
Провод, а также катушку необходимо закрепить в приборе намотке, при этом основу прибора – в приспособлении намотки. Следует проводить спокойные без срывов движения. Опустить провод на каркасную часть.
Между поверхностью, а также проводом должно оставаться 20 сантиметров, чтобы разместить руку на столе для удержания провода. Помимо этого на настольной поверхности должны располагаться дополнительные материалы, без которых невозможно создать собственными руками повышающий трансформатор.
Правой рукой нужно умеренно вращать устройство для намотки, а другой – держать провод
Важно ровная укладка провода. Далее нужно провести изоляцию каркаса, при этом имеющийся на проводе конец следует продеть через отверстие, чтобы быть зафиксированным в области оси прибора намотки.
Начало намотки следует проводить не спеша, максимально аккуратно: важно уметь навыки, чтобы обороты ложились максимально ровно.
Установить счётный прибор на ноль. Склеить изолирующий элемент, либо плотно прижать резиновым кольцом
Все обороты важно делать на пару витков уже в сравнении с предыдущими.
Конструкция и схема трансформатора тока
Обычно трансформаторы тока и амперметры используются вместе как согласованная пара, в которой конструкция трансформатора тока такова, чтобы обеспечить максимальный вторичный ток, соответствующий полномасштабному отклонению амперметра. В большинстве трансформаторов тока существует приблизительное соотношение обратных витков между двумя токами в первичной и вторичной обмотках. Вот почему калибровка трансформатора тока обычно для определенного типа амперметра.
Большинство трансформаторов тока имеют стандартную вторичную номинальную мощность 5 А, при этом первичные и вторичные токи выражаются в таком соотношении, как 100/5. Это означает, что ток первичной обмотки в 20 раз больше, чем ток вторичной обмотки, поэтому, когда в первичном проводнике протекает 100 ампер, во вторичной обмотке будет протекать 5 ампер. Трансформатор тока, скажем, 500/5, будет производить 5 А во вторичной обмотке при 500 А в первичной обмотке, что в 100 раз больше.
Увеличивая количество вторичных обмоток Ns, ток вторичной обмотки можно сделать намного меньшим, чем ток в измеряемой первичной цепи, потому что, когда Ns увеличивается, Is уменьшается пропорционально. Другими словами, число витков и ток в первичной и вторичной обмотках связаны обратно пропорционально.
Трансформатор тока, как и любой другой трансформатор, должен удовлетворять уравнению ампер-виток, и мы знаем из нашего учебника по трансформаторам напряжения с двойной обмоткой, что это отношение витков равно:
из которого мы получаем:
Коэффициент тока устанавливает коэффициент витков, и, поскольку первичный обычно состоит из одного или двух витков, тогда как вторичный может иметь несколько сотен витков, соотношение между первичным и вторичным может быть довольно большим. Например, предположим, что номинальный ток первичной обмотки составляет 100А. Вторичная обмотка имеет стандартный рейтинг 5А. Тогда соотношение между первичным и вторичным токами составляет 100А-5А или 20: 1. Другими словами, первичный ток в 20 раз больше вторичного тока.
Однако следует отметить, что трансформатор тока с номиналом 100/5 не совпадает с трансформатором с номиналом 20/1 или подразделениями 100/5. Это связано с тем, что отношение 100/5 выражает «номинальный ток на входе / выходе», а не фактическое соотношение первичных и вторичных токов. Также обратите внимание, что число витков и ток в первичной и вторичной обмотках связаны обратно пропорционально. Но относительно большие изменения в соотношении витков трансформаторов тока могут быть достигнуты путем изменения первичных витков через окно трансформатора ток, где один первичный виток равен одному проходу, а более одного прохода через окно приводит к изменению электрического соотношения
Но относительно большие изменения в соотношении витков трансформаторов тока могут быть достигнуты путем изменения первичных витков через окно трансформатора ток, где один первичный виток равен одному проходу, а более одного прохода через окно приводит к изменению электрического соотношения.
Так, например, трансформатор тока с отношением, скажем, 300 / 5А можно преобразовать в другой из 150 / 5А или даже 100 / 5А, пропустив основной первичный проводник через его внутреннее окно два или три раза, как показано ниже. Это позволяет более высокому значению трансформатора тока обеспечивать максимальный выходной ток для амперметра, когда используется на меньших первичных линиях тока.
Ссылки по теме
- Правила технической эксплуатации электроустановок потребителей
/ Нормативный документ от 9 февраля 2007 г. в 02:14 - Библия электрика
/ Нормативный документ от 14 января 2014 г. в 12:32 - Справочник по электрическим сетям 0,4-35 кВ и 110-1150 кВ. Том 10
/ Нормативный документ от 2 марта 2009 г. в 18:12 - Кабышев А.В., Тарасов Е.В. Низковольтные автоматические выключатели
/ Нормативный документ от 1 октября 2019 г. в 09:22 - Правила устройства воздушных линий электропередачи напряжением до 1 кВ с самонесущими изолированными проводами
/ Нормативный документ от 30 апреля 2008 г. в 15:00 - Маньков В.Д. Заграничный С.Ф. Защитное заземление и зануление электроустановок
/ Нормативный документ от 27 марта 2020 г. в 09:05 - Князевский Б.А. Трунковский Л.Е. Монтаж и эксплуатация промышленных электроустановок
/ Нормативный документ от 17 октября 2019 г. в 12:36
Монтаж составных частей, требующих разгерметизации бака трансформатора
После выполнения подготовительных работ трансформатор подается по рельсовому пути либо в мастерскую ТМХ, либо в машзал на фундамент или монтажную крестовину.
Монтаж составных частей силового трансформатора ведут без ревизии активной части и подъема «колокола», если не было нарушений условий транспортировки, выгрузки с повреждениями внутри бака трансформатора и хранения их.
Разгерметизацию силового трансформатора для установки составных частей (вводов, цилиндров, ТТ) следует производить в ясную сухую погоду. До этого следует подготовить рабочее место: установить подмости, стеллажи, ограждения. При разгерметизации принимаются меры к предохранению изоляции от увлажнения в процессе монтажа.
Очень эффективным устройством, значительно замедляющим процесс увлажнения изоляции при разгерметизации, является установка осушки воздуха «Суховей». Установка «Суховей» служит для глубокой осушки и очистки от механических примесей воздуха, используемого для подачи в бак трансформатора при его вскрытии, и производстве ревизии активной части. Опыт применения такой установки показывает, что воздух, прошедший через установку «Суховей», во много раз меньше увлажняет твердую изоляцию активной части трансформатора
Время разгерметизации в этом случае может быть значительно увеличено, но при этом не должно превышать 100 ч, а допустимое время разгерметизации больших люков под трансформаторы тока и вводы – 3 ч на каждый.
Работы во время разгерметизации силового трансформатора следует вести по разработанному часовому графику и выполнять с большой осторожностью и аккуратностью во избежание загрязнения внутреннего объема бака и падения внутрь инструментов и посторонних предметов. Монтаж составных частей силового трансформатора производят в следующем порядке
Удаляют из бака бакелитовые цилиндры вводов и крепеж к ним. Снимают транспортные детали и детали крепления отводов Проводят внешний осмотр креплений активной части и состояния механизма и контактов устройства РПН. Устанавливают патрубки вводов, встроенные ТТ. При установке вводов 110 кВ силовых трансформаторов мощностью до 100 МВА масло сливать не требуется.
Для установки ввод следует застропить, поднять, произвести центровку над патрубком, опустить, закрепить его и присоединить токоведущий стержень к отводу обмотки
При монтаже герметичных вводов перед установкой необходимо проверить и отрегулировать давление масла во вводе, обратить особое внимание на правильное размещение и установку соединительных трубок, а также контрольных манометров.
При монтаже наклонных вводов строповка, подъем и установка вводов выполняются с помощью специальной траверсы, полиспаста или талрепов.
После окончания монтажа внутренних частей остатки трансформаторного масла сливают (у трансформаторов, транспортируемых без масла) через донную пробку и герметизируют бак для последующего вакуумирования и заливки или доливки масла в трансформатор
Типы устройств
В зависимости от мощности, конструкции и сферы их применения, существуют такие виды трансформаторов:
- Автотрансформатор конструктивно выполнен как одна обмотка с двумя концевыми клеммами, а также в промежуточных точках устройства имеются несколько терминалов, в которых располагаются первичные и вторичные катушки.
- Трансформатор тока включает в себя первичную и вторичную обмотку, сердечник из магнитного материала, а также оптические датчики, специальные резисторы, позволяющие ускорять способы регулировки напряжения.
- Силовой трансформатор — это устройство, передающее ток, при помощи индукции электромагнитного поля, между двумя контурами. Такие трансформаторы могут быть повышающими или понижающими, сухими или масляными.
- Антирезонансные трансформаторы могут быть как однофазными, так и трёхфазными. Принцип работы такого устройства мало чем отличается от трансформаторов силового типа. Конструктивно представляет собой устройство литого типа с хорошей теплозащитой и полузакрытой структурой. Трансформаторы антирезонансного типа применяются при передаче сигнала на большие расстояния и в условиях больших нагрузок. Идеально подходят для работы в любых климатических условиях.
- Заземляемые трансформаторы (догрузочные). Особенностью этого типа является расположение обмоток в форме звезды или зигзага. Часто заземляемые приборы применяют для подключения счётчика электрической энергии.
- Пик — трансформаторы используются в устройствах радиосвязи и технологиях компьютерного производства, по принципу отделения постоянного и переменного тока. Конструкция такого трансформатора является упрощённой: обмотка с определённым количеством витков расположена вокруг сердечника из ферромагнитного материала.
- Разделительный домашний трансформатор применяется при передаче энергии переменного тока к другому устройству или оборудованию, блокируя при этом способности источника энергии. В бытовых условиях такие приборы обеспечивают регулирование напряжения и гальваническую развязку. Чаще всего применяются для подавления электрических помех в чувствительных приборах и защиты от вредного воздействия электрического тока.
Сборка повышающего трансформатора
Разбирают сердечник. Так как использован О-образный его тип из трансформаторного железа от телевизора, то это легко сделать, так как он состоит из двух половин. Надевают на «рога» обе катушки и соединяют обе части аппарата, зажимают крепежные детали.
Схема устройства однофазного трансформатора.
При использовании отдельных пластин для сборки вначале по мощности трансформатора определяют толщину его пакета и, соответственно, нужное число Ш-образных или О-образных листов (по справочнику). Затем их поочередно вставляют в отверстие на гильзе катушки и стягивают шпильками и гайками (в пластинах есть для этого специальные отверстия).
Если при включении трансформатора слышен шум или дребезг, то надо поплотнее закрутить крепеж. Это делают до тех пор, пока «жужжание» не прекратится. Производят испытание: включают трансформатор в сеть вторичной обмоткой – на первичной стороне должно появиться напряжение 12 В.
Если это условие выполнено, то трансформатор собран правильно.
Расчетная часть
Итак, начнем. Для начала необходимо разобраться, что представляет из себя такое устройство. Трансформатор состоит из двух или более электрических катушек (первичной и вторичной) и металлического сердечника, выполненного из отдельных железных пластин. Первичная обмотка создает магнитный поток в магнитопроводе, а тот в свою очередь индуцирует электрический ток во второй катушке, что показано на схеме ниже. Исходя из соотношения числа витков в первичной и вторичной катушки, трансформатор либо повышает, либо понижает напряжение, пропорционально ему меняется и ток.
От размеров сердечника зависит максимальная мощность, которую трансформатор сможет отдать, поэтому при проектировании отталкиваются от наличия подходящего сердечника. Расчет всех параметров начинается с определения габаритной мощности трансформатора и подключаемой к нему нагрузки. Поэтому сначала нам необходимо найти мощность вторичной цепи. Если вторичная катушка не одна, то их мощность нужно суммировать. Расчетная формула будет иметь вид:
P2=U2*I2
Где:
- U2 — это напряжение на вторичной обмотке;
- I2 — ток вторичной обмотки.
Получив значение, нужно сделать расчет первичной обмотки, учитывая потери на трансформации, предполагаемый КПД около 80%.
P1=P2/0.8=1.25*P2
От значения мощности Р1 подбирается сердечник, его площадь сечения S.
S=√Р1
Где:
- S в сантиметрах;
- Р1 в ватт.
Теперь мы можем узнать коэффициент эффективной передачи и трансформации энергии:
w’=50/S
Где:
- 50 — это частота сети;
- S — сечение железа.
Эта формула дает приблизительное значение, но для простоты расчета вполне подойдет, так как мы изготавливаем деталь в домашних условиях. Далее можно приступить к расчету количества витков, сделать это можно по формуле:
w1=w’*U1
w2=w’*U2
w3=w’*U3
Так как расчет у нас упрощенный и возможна небольшая просадка напряжения под нагрузкой, увеличьте число витков на 10 % от расчетного значения. Далее нужно правильно определить ток наших обмоток, сделать это нужно для каждой обмотки в отдельности по этой формуле:
I1=P1/U1
Определяем диаметр необходимого провода по формуле:
d = 0.8*√I
Исходя из таблицы 1 выбираем провод с искомым сечением. Если подходящего значения нет, нужно сделать округление в большую сторону до табличного диаметра.
Если посчитанного диаметра нет в таблице, или слишком большое заполнение окна получается, то можно взять несколько проводов меньшего сечения и получить в сумме искомое.
Чтобы узнать поместятся ли катушки на нашем самодельном трансформаторе, требуется посчитать площадь окна тр-ра, это образованное сердечником пространство, в которое помещаются катушки. Уже известное число витков умножаем на сечение провода и коэффициент заполнения:
s= w*d²*0.8
Данный расчет производим для всех обмоток, первичной и вторичной, после чего нужно суммировать площадь катушек и сделать сравнение с площадью окна магнитопровода. Окно сердечника должно быть больше площади сечения катушек.
Оцените статью:Как сделать тороидальный трансформатор своими руками
На сегодняшний день многие домашние электрики задумываются о том, как сделать тороидальный трансформатор. Этот спрос на него обеспечен тем, что он имеет сердечник, который значительно лучше по сравнению с другими. Он имеет меньший вес, который может отличаться в полтора раза. Также и КПД этого трансформатора будет значительно выше.
Вот основные причины, которые останавливают многих мастеров при его изготовлении:
- Достаточно сложно найти подходящий сердечник.
- Его изготовление занимает много времени.
Тороидальный трансформатор и его расчет
Для того чтобы значительно облегчить расчет тороидального трансформатора вам необходимо знать следующие данные:
- Выходное напряжение, которое будет подаваться на первичную обмотку U.
- Диаметр сердечника внешний D.
- Внутренний диаметр сердечника d.
- Магнитопровод
Sc = H * (D – d)/2.
Наиболее важной характеристикой сердечника считается площадь его окна S. Этот параметр будет определять интенсивность отвода избытков тепла. Оптимальное значение этого параметра может составлять 80-100 см. Вычисляется он по формуле:
S0 = π * d2 / 4.
Благодаря этим значениям вы легко рассчитаете его мощность по формуле:
P = 1,9 * Sc * S0, где Sc и S0 необходимо брать в квадратных сантиметрах, а P получится в ваттах. Затем вам потребуется найти число витков на один вольт:
k = 50 / Sc.
Когда значение k вам станет известным, то можно будет рассчитать количество витков во вторичной обмотке:
w2 = U2 * k.
Производить расчеты лучше, если в качестве исходного значения использовать напряжение на вторичной обмотке:
W1 = (U1 * w2) / U2, где U1 – это напряжение, которое подводят к первичной обмотке, а U2 снимаемое со вторичной.
Сварочный ток проще всего регулировать с помощью изменения числа витков в первичной обмотке, так как здесь существует меньшое напряжение.
Изготовление тороидального сердечника
Тороидальные трансформаторы содержат в своей конструкции сложный сердечник. Лучшим материалом для его изготовления считается трансформаторная сталь. Для того чтобы изготовить сердечник тороидального трансформатора вам необходимо использовать стальную ленту. Ее необходимо свернуть в рулон, который будет иметь форму Тора. Если у вас уже есть такая форма, то никаких проблем возникнуть не должно.
Хороший готовый сердечник вы также можете найти на лабораторном автотрансформаторе. Вам следует перемотать его обмотки. Измерительные трансформаторы имеют более простой сердечник.
Еще к одному способу изготовления тороидального сердечника относят использование пластин от неисправного промышленного трансформатора. Сначала из этих закрепок вам потребуется изготовить обруч. Его диаметр должен составлять 26 см. Внутрь этого обруча необходимо постепенно вставлять пластины. Следите за тем чтобы они не разматывались.
Намотка тороидального трансформатора
Намотка тороидального трансформатора – это достаточно сложный процесс, который занимает много времени. Тороидальный трансформатор имеет одну из наиболее сложных намоток. Наиболее простым способом считается использование специального челнока. На него следует намотать провод нужной длины и затем его через отверстия. Он имеет сложную конструкцию, но это не влияет на принцип работы трансформатора тороидального. После пропуска через челнок у вас начнет формироваться соответствующая обмотка.
Надеемся, что благодаря этой статье вы самостоятельно сможете изготовить тороидальный трансформатор своими руками.
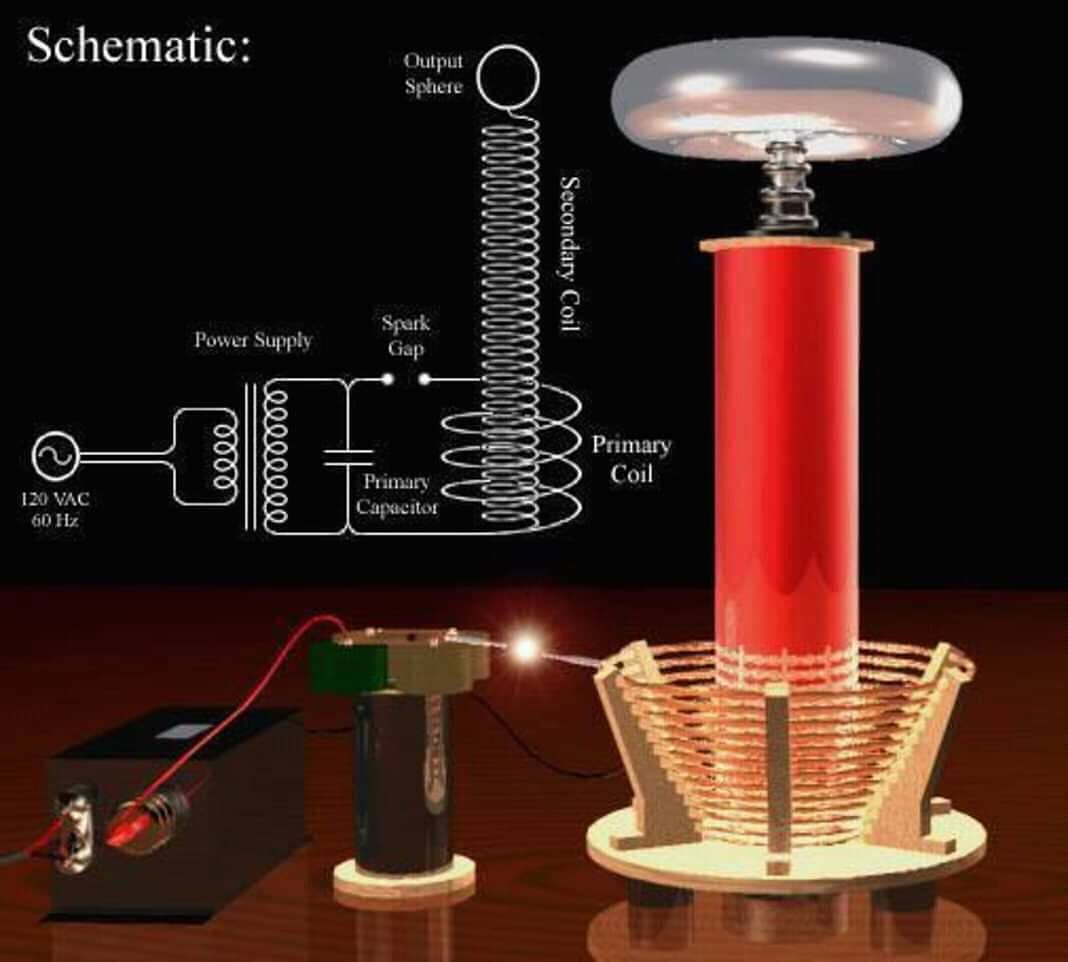
как сделать трансформатор Тесла своими руками?
трансформатор +своими руками | Электрознайка. Домашний Электромастер.
В домашнем хозяйстве бывает необходимо оборудовать освещение в сырых помещениях: подвале или погребе и т.д. Эти помещения имеют повышенную степень опасности поражения электичческим током.
В этих случаях следует пользоваться электрооборудованием рассчитанным на пониженное напряжение питания, не более 42 вольт.
Можно пользоваться электрическим фонарем с батарейным питанием или воспользоваться понижающим трансформатором с 220 вольт на 36 вольт.
Рассчитаем и изготовим однофазный силовой трансформатор 220/36 вольт, с выходным напряжением 36 вольт с питанием от электрической сети переменного тока напряжением 220 вольт.
Для освещения таких помещений подойдет электрическая лампочка на 36 Вольт и мощностью 25 — 60 Ватт. Такие лампочки с цоколем под обыкновенный электропатрон продаются в магазинах электротоваров.
Если вы найдете лампочку на другую мощнось, например на 40 ватт, нет ничего страшного — подойдет и она. Просто трансформатор будет выполнен с запасом по мощности.
Мощность во вторичной цепи: Р_2 = U_2 · I_2 = 60 ватт
Где:
Р_2 – мощность на выходе трансформатора, нами задана 60 ватт;
U_2 — напряжение на выходе трансформатора, нами задано 36 вольт;
I_2 — ток во вторичной цепи, в нагрузке.
КПД трансформатора мощностью до 100 ватт обычно равно не более η = 0,8.
КПД определяет, какая часть мощности потребляемой от сети идет в нагрузку. Оставшаяся часть идет на нагрев проводов и сердечника. Эта мощность безвозвратно теряется.
Определим мощность потребляемую трансформатором от сети с учетом потерь:
Р_1 = Р_2 / η = 60 / 0,8 = 75 ватт.
Мощность передается из первичной обмотки во вторичную через магнитный поток в магнитопроводе. Поэтому от значения Р_1, мощности потребляемой от сети 220 вольт, зависит площадь поперечного сечения магнитопровода S.
Магнитопровод – это сердечник Ш – образной или О – образной формы, набранный из листов трансформаторной стали. На сердечнике будут располагаться первичная и вторичная обмотки провода.
Площадь поперечного сечения магнитопровода рассчитывается по формуле:
S = 1,2 · √P_1.
Где:
S — площадь в квадратных сантиметрах,
P_1 — мощность первичной сети в ваттах.
S = 1,2 · √75 = 1,2 · 8,66 = 10,4 см².
По значению S определяется число витков w на один вольт по формуле:
w = 50/S
В нашем случае площадь сечения сердечника равна S = 10,4 см.кв.
w = 50/10,4 = 4,8 витка на 1 вольт.
Рассчитаем число витков в первичной и вторичной обмотках.
Число витков в первичной обмотке на 220 вольт:
W1 = U_1 · w = 220 · 4.8 = 1056 витка.
Число витков во вторичной обмотке на 36 вольт:
W2 = U_2 · w = 36 · 4,8 = 172.8 витков,
округляем до 173 витка.
В режиме нагрузки может быть заметная потеря части напряжения на активном сопротивлении провода вторичной обмотки. Поэтому для них рекомендуется число витков брать на 5-10 % больше рассчитанного. Возьмем W2 = 180 витков.
Величина тока в первичной обмотке трансформатора:
I_1 = P_1/U_1 = 75/220 = 0,34 ампера.
Ток во вторичной обмотке трансформатора:
I_2 = P_2/U_2 = 60/36 = 1,67 ампера.
Диаметры проводов первичной и вторичной обмоток определяются по значениям токов в них исходя из допустимой плотности тока, количества ампер на 1 квадратный миллиметр площади проводника. Для трансформаторов плотность тока, для медного провода, принимается 2 А/мм² .
При такой плотности тока диаметр провода без изоляции в миллиметрах определяется по формуле: d = 0,8√I .
Для первичной обмотки диаметр провода будет:
d_1 = 0,8 · √1_1 = 0,8 · √0,34 = 0,8 · 0,58 = 0,46 мм. Возьмем 0,5 мм.
Диаметр провода для вторичной обмотки:
d_2 = 0,8 · √1_2 = 0,8 · √1,67 = 0,8 · 1,3 = 1,04 мм. Возьмем 1,1 мм.
ЕСЛИ НЕТ ПРОВОДА НУЖНОГО ДИАМЕТРА, то можно взять несколько, соединенных параллельно, более тонких проводов. Их суммарная площадь сечения должна быть не менее той, которая соответствует рассчитанному одному проводу.
Площадь поперечного сечения провода определяется по формуле:
s = 0,8 · d².
где: d — диаметр провода.
Например: мы не смогли найти провод для вторичной обмотки диаметром 1,1 мм.
Площадь поперечного сечения провода диаметром 1,1 мм. равна:
s = 0,8 · d² = 0,8 · 1,1² = 0,8 · 1,21 = 0,97 мм².
Округлим до 1,0 мм².
Из таблицы выбираем диаметры двух проводов сумма площадей сечения которых равна 1.0 мм².
Например, это два провода диаметром по 0,8 мм. и площадью по 0,5 мм².
Или два провода:
— первый диаметром 1,0 мм. и площадью сечения 0,79 мм²,
— второй диаметром 0,5 мм. и площадью сечения 0,196 мм².
что в сумме дает: 0,79 + 0,196 = 0,986 мм².
Намотка катушки ведется двумя проводами одновременно, строго выдерживается равное количество витков обоих проводов. Начала этих проводов соединяются между собой. Концы этих проводов также соединяются.
Получается как бы один провод с суммарным поперечным сечением двух проводов.
Смотрите статьи:— «Как намотать трансформатор на Ш-образном сердечнике».
— «Как изготовить каркас для Ш — образного сердечника».
Как рассчитать и намотать трансформатор своими руками? FAQ
Как рассчитать и намотать силовой низкочастотный трансформатор для блока питания УНЧ? FAQ Часть 1
Эта тема возникла в связи с написанием статьи о самодельном усилителе низкой частоты. Хотел продолжить повествование, рассказав о блоке питания и добавив ссылку на какую-нибудь популярную статью о перемотке трансформаторов, но не нашёл простого понятного описания. Что ж поделаешь, всё нужно делать самому. https://oldoctober.com/
В этом опусе я расскажу, на примере своей конструкции, как рассчитать и намотать силовой трансформатор для УНЧ. Все расчёты сделаны по упрощённой методике, так как в подавляющем большинстве случаев, радиолюбители используют уже готовые трансформаторы. Статья рассчитана на начинающих радиолюбителей.
Самые интересные ролики на Youtube
Те же, кто хочет углубиться в расчёты, может скачать очень хорошую книжку с примерами полного расчёта трансформатора, ссылка на которую есть в конце статьи. Также в конце статьи есть ссылка на несколько программ для расчёта трансформаторов.
Близкие темы.
Блок питания для усилителя низкой частоты из доступных деталей. УНЧ, часть 3.
Как подружить Блокнот с Калькулятором Windows, чтобы облегчить расчёты?
Оглавление статьи.
- Как определить необходимую мощность силового трансформатора для питания УНЧ?
- Какую схему питания УНЧ выбрать?
- Расчёт выходного напряжения (переменного тока) трансформатора работающего на холостом ходу или без существенной нагрузки.
- Расчёт напряжения (постоянного тока) на выходе блока питания работающего при максимальной нагрузке.
- Типы магнитопроводов силовых трансформаторов.
- Как определить габаритную мощность трансформатора?
- Где взять исходный трансформатор?
- Как подключить неизвестный трансформатор к сети?
- Как сфазировать обмотки трансформатора?
- Как определить количество витков вторичной обмотки?
- Как рассчитать диаметр провода для любой обмотки?
- Как измерить диаметр провода?
- Как рассчитать количество витков первичной обмотки?
- Как разобрать и собрать трансформатор?
- Как намотать трансформатор?
- Как закрепить выводы обмоток трансформатора?
- Как изменить напряжение на вторичной обмотке не разбирая трансформатор?
- Программы для расчёта силовых трансформаторов.
- Дополнительные материалы к статье.
Страницы 1 2 3 4
Как определить необходимую мощность силового трансформатора для питания УНЧ?
Для колонок описанных здесь, я решил собрать простой усилитель мощностью 8-10 Ватт в канале, на самых дешёвых микросхемах, которые только удалось найти на местном радиорынке. Ими оказались – TDA2030 ценой всего по 0,38$.
Предполагаемая мощность в нагрузке должна составить 8-10 Ватт в канале:
10 * 2 = 20W
КПД микросхемы TDA2030 по даташиту (datasheet) – 65%.
20 / 0,65 = 31W
Я подобрал трансформатор с витым броневым магнитопроводом, так что, КПД можно принять равным – 90%.https://oldoctober.com/
31 / 0,9 = 34W
Приблизительно оценить КПД трансформатора можно по таблице.
| Мощность трансформатора (Вт) | КПД трансформатора (%) | |||
| Броневой штампованный | Броневой витой | Стержневой витой | Кольцевой | |
| 5-10 | 60 | 65 | 65 | 70 |
| 10-50 | 80 | 90 | 90 | 90 |
| 50-150 | 85 | 93 | 93 | 95 |
| 150-300 | 90 | 95 | 95 | 96 |
| 300-1000 | 95 | 96 | 96 | 96 |
Значит, понадобится сетевой трансформатор мощностью около 30-40 Ватт. Такой трансформатор должен весить около килограмма или чуть больше, что, на мой взгляд, прибавит моему мини усилителю устойчивости и он не будет «бегать» за шнурами.
Если мощность трансформатора больше требуемой, то это всегда хорошо. У более мощных трансформаторов выше КПД. Например, трансформатор мощностью 3-5 Ватт может иметь КПД всего 50%, в то время как у трансформаторов мощностью 50–100 Ватт КПД обычно около 90%.
Итак, с мощностью трансформатора вроде всё более или менее ясно.
Теперь нужно определиться с выходным напряжением трансформатора.
Вернуться наверх к меню
Какую схему питания УНЧ выбрать?
Для питания микросхемы, я решил использовать двухполярное питание.
При двухполярном питании не требуется бороться с фоном и щелчками при включении. Кроме того, отпадает необходимость в разделительных конденсаторах на выходе усилителя.
Ну, и самое главное, микросхемы, рассчитанные на однополярное питание и имеющие соизмеримый уровень искажений, в несколько раз дороже.
Это схема блока питания. В нём применён двухполярный двухполупериодный выпрямитель, которому требуются трансформатор с двумя совершенно одинаковыми обмотками «III» и «IV» соединёнными последовательно. Далее все основные расчёты будут вестись только для одной из этих обмоток.
Обмотка «II» предназначена для питания электронных регуляторов громкости, тембра и стереобазы, собранных на микросхеме TDA1524. Думаю описать темброблок в одной из будущих статей.
Ток, протекающий через обмотку «II» будет крайне мал, так как микросхема TDA1524 при напряжении питания 8,5 Вольта потребляет ток всего 35мА. Так что потребление здесь ожидается менее одного Ватта и на общей картине сильно не отразится.
Вернуться наверх к меню
Расчёт выходного напряжения (переменного тока) трансформатора работающего на холостом ходу или без существенной нагрузки.
Этот расчёт необходимо сделать, чтобы обезопасить микросхему от пробоя.
Максимальное допустимое напряжение питания TDA2030 – ±18 Вольт постоянного тока.
Для переменного тока, это будет:
18 / 1,41 ≈ 12,8 V
Падение напряжения на диоде* выпрямителя при незначительной нагрузке – 0,6 V.
12,8 + 0,6 = 13,4 V
*Схема применённого выпрямителя построена так, что протекающий в любом направлении ток создаёт падение напряжения только на одном из диодов. При использовании одной вторичной обмотки и мостового выпрямителя, таких диодов будет два.
При повышении напряжения сети, напряжение на выходе выпрямителя увеличится. По нормативам, напряжение сети должно быть в пределах – -10… +5% от 220-ти Вольт.
Уменьшаем напряжение на вторичной обмотке трансформатора для компенсации повышения напряжения сети на 5%.
13,4 * 0.95 ≈ 12,7 V
Мы получили значение максимального допустимого напряжения переменного тока на вторичной обмотке трансформатора при питании микросхемы TDA2030 от двухполярного источника без стабилизации напряжения.
Проще говоря, это чтобы напряжение не вылезло за пределы ±18V и не спалило микруху.
Те же значения для этой линейки микросхем.
| Тип микросхемы | На выходе трансформатора (~В) | Напряжение питания max (±В) |
| TDA2030 | 12,7 | 18 |
| TDA2040 | 14 | 20 |
| TDA2050 | 17,4 | 25 |
Вернуться наверх к меню
Расчёт напряжения (постоянного тока) на выходе блока питания работающего при максимальной нагрузке.
Этот расчёт необходимо сделать, чтобы оценить максимальную мощность на нагрузке и ограничить её путём снижения напряжения, если она выйдет за допустимые пределы для данного типа микросхемы или нагрузки.
Под нагрузкой напряжение переменного тока на вторичной обмотке понижающего трансформатора может уменьшиться.
12,7 * 0.9 ≈ 11,4V
Падение напряжения на диоде* выпрямителя резко возрастёт под нагрузкой и может достигнуть, в зависимости от типа диода, – 0.8… 1,5V.
11,4 – 1,5 = 9,9V
*Схема применённого выпрямителя построена так, что протекающий в любом направлении ток создаёт падение напряжения только на одном из диодов. При использовании одной вторичной обмотки и мостового выпрямителя, таких диодов будет два.
После выпрямителя получаем на конденсаторе фильтра напряжение постоянного тока:
9,9 * 1,41 ≈ 14V
Но, под нагрузкой, конденсатор не будет успевать заряжаться до максимально возможного напряжения. Поэтому, и в этом случае, исходное напряжение увеличивают на 10%.
14 * 0.9 = 12,6V
В реальности, действующее напряжение может быть и выше, а 12,6 Вольта, это тот уровень, на котором предположительно возникнет ограничение аудио сигнала. На картинке изображён эпюр напряжения на нагрузке, снятый при воспроизведении частоты синусоидального сигнала. Сигнал ограничен напряжением питания УНЧ.
При ограничении сигнала возникают сильные искажения, которые фактически и ограничивают выходную мощность УНЧ.
По даташиту, при напряжении питания ±12,6 Вольта и нагрузке 4 Ω, микросхема TDA2030 развивает синусоидальную мощность 9 Ватт. Этой мощности вполне хватит для моих скромных колонок и она не выйдет за пределы допуска для TDA2030.
Выходная мощность микросхем этой серии на нагрузке 4 Ω при использовании нестабилизированного блока питания с максимальным допустимым напряжением.
| Тип микросхемы | Мощность на нагрузке (Вт) | Напряжение питания на выходе БП под нагр. (±В) |
| TDA2030 | 9 | 12,6 |
| TDA2040 | 22 | 14 |
| TDA2050 | 35 | 18 |
Получив необходимые исходные данные, можно приступать к перемотке трансформатора.
Вернуться наверх к меню
Страницы 1 2 3 4
Как Сделать Трансформатор На 500 Вт Из Автотрансформатора Трансформатор Своими Руками
Как Сделать Трансформатор На 500 Вт Из Автотрансформатора Трансформатор Своими Руками. В этом ролике я покажу, как из автотрансформатора сделать трансформатор. Автотрансформатор будем снимать с стабилизатора напряжения Elim СНАП-500. Почему я решил снять автотрансформатор с этого стабилизатора, несмотря на то что он рабочий? На этом стабилизаторе стоит автотрансформатор на 500 ватт, а мне нужен трансформатор на 500 ватт. Я искал такой трансформатор везде, и в магазинах, и на авито и у знакомых электриков. Но нигде не нашел. Тогда я принял решение снять автотрансформатор с этого стабилизатора, и переделать его в трансформатор. Поддержите автора канала
— Обзор стабилизатора напряжения Elim СНАП-500
Электромеханический стабилизатор и реле напряжения
Установка и подключение китайского реле напряжения
Обзор ЛАТР SUNTEK 1000ВА, который будет подключаться к трансформатору.
Лучшие видео по ремонту
Лучшие видео по электрике
курс «Сам Себе Электрик»
00:00 — Как сделать трансформатор из автотрансформатора
00:34 — Почему я решил снять автотрансформатор со стабилизатора напряжения?
01:13 — Как снять автотрансформатор со стабилизатора напряжения?
01:34 — В чем сложность снятия автотрансформатора со стабилизатора.
01:51 — Какие выводы имеет снятый автотрансформатор?
02:44 — Как мы будем подключать первичную обмотку в наших опытах.
02:58 — Прозвонка обмотки автотрансформатора.
03:21 — Последовательность дальнейшей переделки автотрансформатора.
03:33 — Как определить, сколько витков нам нужно намотать во вторичной обмотке.
04:02 — Автотрансформатор после намотки тестовой обмотки.
04:18 — Замер выходного напряжения тестовой обмотки.
04:56 — Изоляция не используемых выводов автотрансформатора.
05:10 — Какие напряжения нам нужны на вторичной обмотке?
05:20 — Подсчет количества витков на вторичной обмотке.
05:56 — Наш трансформатор после намотки вторичной обмотки.
06:21 — Замер напряжения на вторичной обмотке.
06:43 — Вход и выход сделанного трансформатора.
07:04 — Возможности для апгрейда трансформатора.
07:11 — Теплоотвод трансформатора.
07:27 — Планы по размещению этого трансформатора в корпусе стабилизатора.
07:44 — Поддержите видео о реле напряжения лайком, репостом и комментарием.
Помогу развить ваш канал
Подпишитесь на наш канал
Консультация
Блог «Электрика и ремонт»
Мои книги
Мой аккаунт в соц-сети
Мой email msnbel />
Лучшие видео «Дом своими руками»
Лучшие видео «Электрика своими руками»
Лучшие видео «Сантехника своими руками»
Лучшие видео «Ремонт своими руками»
Лучшие видео «Профессия электрик, строитель»
- Категория
- Игры
Комментарии выключены
Вместе с Как Сделать Трансформатор На 500 Вт Из Автотрансформатора Трансформатор Своими Руками так же смотрят:
Самодельный трансформатор — Техножук
Изготовление трансформатора лучше всего начать с сердечника. Для сердечника надо нарезать из жести от консервных банок сорок пластин по рис. 71 а. Из этих пластин мы и соберем Ш-образный сердечник. Как видно из рисунка, средняя полоска пластинки несколько врезается в поперечную полоску. Пластинки вырубаются зубилом и после тщательно зачищаются напильником. Когда все пластинки нарезаны, их надо отжечь. Для этого пластинки кладут на горячие угли, потом в золу только что истопившейся печи и оставляют их там на несколько часов. После этого с пластин счищается окалина, и с одной стороны они покрываются лаком. Если не найдется зубила, то пластинки можно вырезать ножницами по рис. 71 б.
Изготовление трансформатора лучше всего начать с сердечника. Для сердечника надо нарезать из жести от консервных банок сорок пластин по рис. 71 а. Из этих пластин мы и соберем Ш-образный сердечник. Как видно из рисунка, средняя полоска пластинки несколько врезается в поперечную полоску. Пластинки вырубаются зубилом и после тщательно зачищаются напильником. Когда все пластинки нарезаны, их надо отжечь. Для этого пластинки кладут на горячие угли, потом в золу только что истопившейся печи и оставляют их там на несколько часов. После этого с пластин счищается окалина, и с одной стороны они покрываются лаком. Если не найдется зубила, то пластинки можно вырезать ножницами по рис. 71 б.
Пока пластинки сохнут, мы займемся изготовлением катушки трансформатора. Катушка склеивается из тонкого картона по рис.71 в.На сердечник катушки наматывается несколько слоев кальки и затем производится намотка проволоки.
Для первичной обмотки трансформатора на 120 вольт надо намотать 2500 витков изолированной эмалью проволоки диаметром 0,13мм. Прежде чем начинать намотку, к проволоке припаивается гибкий проводник сантиметров 15 длины, затем, обмотав его несколько раз вокруг сердечника, оставляют свободный конец в 6—7 см, и намотка катушки ведется ровным слоем по всей длине сердечника. К концу первичной обмотки также припаивается гибкий проводничсж и закрепляется на щечке катушки.
Покрыв первичную обмотку катушки несколькими слоями кальки, наматывают на нее в том же направлении вторичную обмотку. Для вторичной обмотки трансформатора надо намотать 120 витков изолированного эмалью провода диаметром 0,45мм. При этой обмотке мы сможем получать напряженнее 6 вольт, что вполне достаточно для питания лампы 6Ф6.
Рис. 71. Детали трансформатора.
а—шаблон пластин для сердечника трансформатора, б—можно вырезать пластины и так, в—каркас катушки трансформатора, г—готовый трансформатор „Гном\».
Закончив вторичную обмотку, катушку покрывают изоляционной лентой или же дерматином. Можно покрыть катушку и несколькими слоями кальки, а затем плотной бумагой. Всё это необходимо для предохранения обмотки от случайных повреждений.
Сборка трансформатора производится так: катушка кладется на стол, затем берется пластинка, средняя полоска несколько отгибается и вставляется в катушку. Вторую полоску вставляют в катушку с другой стороны, третью—так же, как и первую, и т. д. При сборке пластин следует обращать внимание на то, чтобы покрытая лаком сторона одной пластинки всегда ложилась .на непокрытую лаком сторону другой. В катушку надо вставить как можно больше пластин, чтобы сердечник был плотнее. Вставляя последние пластины будьте осторожны, чтобы не прорезать картон катушки и не повредить обмотку.
Собранный сердечник стягивается деревянными или металлическими планками на болтиках или же металлическими скобами. Готовый трансформатор „Гном\» показан на рис. 71г.
Обмотка собственных трансформаторов A M I F.
На рисунке 21 показаны все катушки, которые я намотал на шпульки до настоящего времени. Одна пустая шпулька служит для обозначения последних четырех, на которые нанесен клей Crystal Clear Gorilla Glue. Эти катушки были изготовлены с целью тестирования продукта, известного как Q Dope, на резиновый клей и клей Gorilla Glue. Q Dope выделяет довольно ядовитые пары, и я бы предпочел не использовать его. Добротность катушки, обработанной им, не лучше, чем у катушек, обработанных резиновым клеем.На самом деле это немного хуже, но при размере выборки в одну катушку нельзя делать однозначных выводов. Те, которые были обработаны клеем Crystal Clear Gorilla Glue, оказались лучше, чем резиновым клеем или Q Dope. Результаты приведены в таблице ниже.
| Таблица 2, добротность, индуктивность и резонанс C. | Измерено на частоте 790 кГц. | Измерено на частоте 455 кГц. | ||||
|---|---|---|---|---|---|---|
| Катушка # | Q | л (мГн) | Q | Cr (пФ) | л (мГн) Рассчитано | Легированный. |
| 1 | 97 | 0,92 | 83 | 147 | 0,832 | Резиновый цемент. |
| 2 | 80 | 0,93 | 82 | 149 | 0,821 | Q Допинг. |
| 3 | 99 | 0,860 | 82 | 148 | 0,827 | Резиновый цемент. |
| 4 | 104 | 0.915 | 83 | 146 | 0,838 | Резиновый цемент. |
| 5 | 99 | 0,94 | 84 | 144 | 0,850 | Резиновый цемент. |
| 6 | 105 | 0,925 | 84 | 140 | 0,874 | Резиновый цемент. |
| 7 | 98 | 0,98 | 81 | 140 | 0.874 | Резиновый цемент. |
| 8 | 88 | 0,915 | 71 | 149 | 0,821 | * Неправильная шпулька. |
| 9 | 103 | 0,905 | 84 | 148 | 0,827 | CCGG. |
| 10 | 95 | 0,905 | 82 | 146 | 0,838 | CCGG. |
| 11 | 94 | 0,950 | 84 | 146 | 0,838 | CCGG. |
| 12 | 94 | 0,920 | 83 | 146 | 0,838 | CCGG. |
CCGG = Кристально чистый клей гориллы.
* Легированный CCGG. Сью принесла домой не те шпульки. Я решил использовать один, чтобы посмотреть, как все пойдет.Все прошло не очень хорошо. И центральное отверстие, и отверстия для ввода и вывода проволоки необходимо было просверлить.
Единственный столбец в приведенной выше таблице, который требует небольшого пояснения, — это «Рассчитано L (мГн)» в столбце «Измерено на 455 кГц». Индуктивность рассчитывалась для каждого измерения по формуле
L = 1 / (4pi 2 f 2 C)Где L — индуктивность в генри, f — частота в герцах, а C — показание шкалы емкости в пикофарадах. Кажущееся несоответствие между значениями индуктивности при 790 и 455 кГц легко объяснить собственной емкостью катушки, из-за которой индуктивность кажется больше при измерении вблизи частоты собственного резонанса.
Q Dope неприятен в использовании, поэтому я сделал с ним только одну катушку. Резиновый клей, ну, резиновый клей. Кристально чистый клей Gorilla Glue — новый продукт, и читатель может быть с ним не знаком. Он почти не имеет запаха. При растирании между большим пальцем и пальцем появляется ощущение жирности. Нет ни малейшего признака того, что он хочет склеить пальцы. Поверхность становится липкой примерно через два часа после нанесения. После высыхания в течение ночи поверхность кажется твердой и сухой.При нанесении на катушку он впитывается так же быстро, как Q Dope, и оставляет отдельные витки четко видимыми. Обработанная часть змеевика выглядит немного темнее, чем необработанная.
Думаю, не многие из читателей этой статьи будут наматывать таким образом собственные катушки. Для дублирования моего проекта вам понадобятся два намотчика катушек Морриса. Мне дали тот, в котором не было проводника. Я нашел еще один на eBay, который выглядит так, как будто он был собран из частей нескольких единиц.Тем не менее, у меня была хорошая коллекция деталей и достаточно изобретательности, чтобы перепрофилировать некоторые обычные предметы и сделать работающий намотчик катушек.
Некоторые могут назвать меня ленивым из-за моторизации намоточного устройства, но я думаю, что это действительная модификация, которую другие, у кого уже есть намотчик, могут захотеть продублировать. С двигателем, обеспечивающим мощность, у меня есть обе руки, чтобы применить сопротивление к проводу, если необходимо, и наблюдать за процессом, чтобы убедиться, что все идет хорошо. Это далеко не то, чтобы повернуть рукоятку одной рукой, удерживать моталку от скольжения по скамейке другой и воздействовать на проволоку другой рукой.Подождите минуту. У меня просто кончились руки? Кроме того, я использовал шаговый двигатель и купил контроллер, вместо того, чтобы пытаться собрать его самостоятельно. Это означает, что двигатель может работать на части своей максимальной скорости и при этом работать так же плавно, как двигатель с пониженным редуктором. Я работал на нем со скоростью 1 оборот в секунду. Это означает, что на намотку катушки на 300 витков требуется 5 минут.
Капитан Кирк Скотти. «Вы спешите, мистер Скотт?»
Абсолютно постоянная скорость намотки должна приводить к более однородным катушкам.Стоимость двух двигателей и двух плат контроллеров плюс доставка из Китая составляла немногим более 100 долларов. Хотя многие веб-сайты говорят, что у них есть шаговые двигатели, большинство из них не дают спецификации крутящего момента, поэтому вы не можете быть уверены, что получаете двигатель, который будет выполнять эту работу.
Причина использования двух двигателей — мой план запустить вал катушки от одного двигателя и кулачковый вал от другого. Управляя скоростью двигателя с помощью Arduino, я могу установить любое передаточное число, которое захочу. Если вы не хотите заходить так далеко, вы можете моторизировать имеющуюся намоточную машину за половину стоимости.На данный момент я работаю с одним двигателем и использую передаточное число от 22 до 21, предоставленное господином Моррисом.
Проводник.
Деревянная часть направляющей для проволоки была вырезана из доски толщиной 3/4 дюйма, которую я купил в домашнем центре. Если вы не плотник, вам может показаться странным, что доску размером 3 и 1/2 на 3/4 дюйма называют 1 на 4. Поскольку вам нужен такой маленький кусок, вы должны попробовать пойти на склад пиломатериалов и просят просмотреть их записки. Они могут взимать символическую плату или просто дать вам небольшую сумму. Просверлите отверстие 1/4 дюйма в одном конце, как показано на Рисунке 10.
Выберите иглу с ушком, достаточно большим, чтобы позволить проволоке гладко проходить через нее.
Воткните эту иглу в торцевую жилу деревянной детали по центру, вверх, вниз и слева направо. Расположите нижний конец проушины над центром вала катушки.
Убедитесь, что игла вращается так, чтобы проволока проходила через ушко вертикально. См. Рисунок 22.
Процедура намотки катушки.
BERT для чайников — Пошаговое руководство | Мишель Кана, доктор философии
Чат-боты, виртуальный помощник и диалоговые агенты обычно классифицируют запросы по конкретным намерениям, чтобы генерировать наиболее последовательный ответ. Классификация намерений — это проблема классификации, которая предсказывает метку намерения для любого заданного пользовательского запроса. Обычно это проблема классификации нескольких классов, когда запросу присваивается одна уникальная метка. Например, запрос «сколько стоит услуга лимузина в Питтсбурге» обозначается как «Groundfare», а запрос «какой вид наземного транспорта доступен в Денвере» — как «ground_service».Запрос «я хочу вылететь из Бостона в 8:38 и прибыть в Денвер в 11:10» — это намерение «рейс», а «показать мне стоимость и время перелетов из Сан-Франциско в Атланту» — «авиабилеты + flight_time »намерение.
Примеры выше показывают, насколько неоднозначной может быть метка намерений. Пользователи могут добавлять вводящие в заблуждение слова, в результате чего в одном запросе присутствует несколько намерений. Для классификации намерений были предложены методы обучения на основе внимания (Liu and Lane, 2016; Goo et al., 2018). Один тип сети, построенной с особым вниманием, называется трансформатором . Он применяет механизмы внимания для сбора информации о релевантном контексте данного слова, а затем кодирует этот контекст в богатый вектор, который грамотно представляет это слово.
В этой статье мы продемонстрируем Transformer, особенно то, как его механизм внимания помогает в решении задачи классификации намерений путем изучения контекстных отношений. После демонстрации ограничений классификатора на основе LSTM мы представляем BERT: предварительное обучение глубоких двунаправленных преобразователей, новый подход преобразователя, предварительно обученный на больших корпусах и с открытым исходным кодом.В последней части этой статьи представлен код Python, необходимый для точной настройки BERT для задачи классификации намерений и достижения высочайшей точности в запросах с невидимыми намерениями. Мы используем набор данных ATIS (Airline Travel Information System), стандартный набор эталонных данных, широко используемый для распознавания намерений, стоящих за запросом клиента.
Данные
В одной из наших предыдущих статей вы найдете код Python для загрузки набора данных ATIS. В наборе данных обучения ATIS у нас есть 26 различных намерений, распределение которых показано ниже.Набор данных сильно несбалансирован, большинство запросов помечены как «полет» (код 14).
Мультиклассификатор
Прежде чем рассматривать Transformer, мы реализуем простую рекуррентную сеть LSTM для решения задачи классификации. После обычной предварительной обработки, токенизации и векторизации 4978 выборок подаются на слой Keras Embedding, который проецирует каждое слово как вложение Word2vec размерности 256. Результаты передаются через слой LSTM с 1024 ячейками. Это дает 1024 вывода, которые передаются на плотный слой с 26 узлами и активацией softmax.Вероятности, созданные в конце этого конвейера, сравниваются с исходными метками с использованием категориальной кроссэнтропии.
Как видно из результатов обучения выше, оптимизатор Adam застревает, потери и точность не улучшаются. Модель, кажется, предсказывает «полет» большинства классов на каждом этапе.
Когда мы используем обученную модель для прогнозирования намерений в невидимом тестовом наборе данных, матрица путаницы ясно показывает, насколько модель подходит для большинства «летных» классов.
Увеличение данных
Работа с несбалансированным набором данных — обычная проблема при решении задачи классификации. Увеличение объема данных — это то, что приходит на ум как хороший обходной путь. Здесь нередко можно встретить алгоритм SMOTE как популярный выбор для увеличения набора данных без искажения прогнозов. SMOTE использует классификатор k-ближайших соседей для создания синтетических точек данных в качестве многомерной интерполяции тесно связанных групп истинных точек данных. К сожалению, у нас есть 25 классов меньшинств в наборе данных обучения ATIS, в результате чего остается один слишком репрезентативный класс.SMOTE не работает, так как не может найти достаточно соседей (минимум 2). Передискретизация с заменой является альтернативой SMOTE, которая также не улучшает прогнозные характеристики модели.
Набор данных SNIPS, который собирается с помощью персонального голосового помощника Snips, более позднего набора данных для понимания естественного языка, представляет собой набор данных, который можно использовать для расширения набора данных ATIS в будущем.
Двоичный классификатор
Поскольку нам не удалось полностью расширить набор данных, сейчас мы скорее уменьшим масштаб проблемы.Мы определяем задачу бинарной классификации, в которой «полетные» запросы сравниваются с остальными классами, сворачивая их в один класс, называемый «другой». Распределение меток в этом новом наборе данных показано ниже.
Теперь мы можем использовать ту же сетевую архитектуру, что и раньше. Единственное изменение заключается в уменьшении количества узлов в плотном слое до 1, функции активации до сигмоида и функции потерь до бинарной кроссэнтропии. Удивительно, но модель LSTM все еще не может научиться предсказывать намерение, учитывая пользовательский запрос, как мы видим ниже.
Через 10 эпох мы оцениваем модель на невидимом тестовом наборе данных. На этот раз все образцы предсказываются как «другие», хотя «полет» имел в обучающем наборе более чем в два раза больше образцов, чем «другие».
Причина, по которой мы сейчас смотрим на Transformer, — это плохой результат классификации, который мы наблюдали с моделями от последовательности к последовательности в задаче Intent Classification, когда набор данных несбалансирован. В этом разделе мы представляем вариант Transformer и реализуем его для решения нашей проблемы классификации.Мы особенно внимательно рассмотрим опубликованные в конце 2018 года представления двунаправленного кодера от трансформаторов (BERT).
Что такое BERT?BERT — это, по сути, обученный стек Transformer Encoder, с двенадцатью в базовой версии и двадцатью четырьмя в большой версии, по сравнению с 6 уровнями кодировщика в исходном Transformer, который мы описали в предыдущей статье.
КодерыBERT имеют более крупные сети с прямой связью (768 и 1024 узлов в базовом и большом соответственно) и больше головок внимания (12 и 16 соответственно).BERT прошел обучение по Википедии и Книжному корпусу, набору данных, содержащему более 10 000 книг разных жанров. Ниже вы можете увидеть схему дополнительных вариантов BERT, предварительно обученных на специализированных корпусах.
исходный кодBERT был выпущен для общественности как новая эра в НЛП. Его код модели с открытым исходным кодом побил несколько рекордов для сложных языковых задач. Предварительно обученная модель на массивных наборах данных позволяет любому, кто занимается обработкой естественного языка, использовать этот бесплатный инструмент. Теоретически BERT позволяет нам пройти несколько тестов с минимальной тонкой настройкой под конкретную задачу.
(источник: Джей. Аламмар, 2018 г.)BERT работает аналогично стеку кодировщика Transformer, принимая в качестве входных данных последовательность слов, которые продолжают течь вверх по стеку от одного кодировщика к другому, пока поступают новые последовательности. вывод для каждой последовательности представляет собой вектор из 728 чисел в базовой версии или 1024 в большой версии. Мы будем использовать такие векторы для нашей задачи классификации намерений.
Зачем нам BERT?
Правильное представление языка является ключом к общему пониманию языка машинами. Контекстно-свободные модели , такие как word2vec или GloVe, генерируют представление встраивания одного слова для каждого слова в словаре. Например, слово «банк» будет иметь одинаковое представление в «банковский депозит» и «берег реки». Контекстные модели вместо этого генерируют представление каждого слова, основанное на других словах в предложении. BERT, как контекстная модель, двунаправленно фиксирует эти отношения. BERT был основан на недавней работе и умных идеях в области контекстных представлений перед обучением, включая полу-контролируемое последовательное обучение, генеративное предварительное обучение, ELMo, преобразователь OpenAI, ULMFit и преобразователь.Хотя все эти модели являются однонаправленными или неглубоко двунаправленными, BERT полностью двунаправлен.
Мы будем использовать BERT для извлечения высококачественных языковых функций из текстовых данных запроса ATIS и точной настройки BERT для конкретной задачи (классификации) с собственными данными для создания современных прогнозов.
Подготовка среды BERTНе стесняйтесь загрузить оригинальный блокнот Jupyter, который мы адаптируем для нашей цели в этом разделе.
Что касается среды разработки, мы рекомендуем Google Colab с предложением бесплатных графических процессоров и TPU, которые можно добавить, перейдя в меню и выбрав: Правка -> Настройки ноутбука -> Добавить ускоритель (GPU) .Альтернативой Colab является использование экземпляра JupyterLab Notebook на облачной платформе Google, выбрав меню AI Platform -> Notebooks -> New Instance -> Pytorch 1.1 -> With 1 NVIDIA Tesla K80 после запроса Google на увеличение вашего Квота GPU. Это будет стоить ок. 0,40 доллара в час (текущая цена, которая может измениться). Ниже вы найдете код для проверки доступности вашего графического процессора.
Мы будем использовать интерфейс PyTorch для BERT от Hugging Face, который на данный момент является наиболее широко распространенным и самым мощным интерфейсом PyTorch для работы с BERT.Hugging Face предоставляет репозиторий pytorch-transformers с дополнительными библиотеками для взаимодействия с более предварительно обученными моделями для обработки естественного языка: GPT, GPT-2, Transformer-XL, XLNet, XLM.
Как вы можете видеть ниже, для того, чтобы torch мог использовать графический процессор, вы должны идентифицировать и указать графический процессор в качестве устройства, потому что позже в цикле обучения мы загружаем данные на это устройство.
Теперь мы можем загрузить наш набор данных в экземпляр ноутбука. Пожалуйста, запустите код из нашей предыдущей статьи, чтобы предварительно обработать набор данных с помощью функции Python load_atis () , прежде чем двигаться дальше.
BERT ожидает входных данных в определенном формате с специальными маркерами для обозначения начала ([CLS]) и разделения / конца предложений ([SEP]). Кроме того, нам нужно разметить нашего текста в токены, соответствующие словарю BERT.
'[CLS] я хочу вылететь из Бостона в 838 и прибыть в Денвер в 1110 утра [SEP]' ['[CLS]', 'i', 'want', 'to', 'fly' , 'from', 'boston', 'at', '83', '## 8', 'am', 'and', 'прибыть', 'in', 'denver', 'at', '111' , '## 0', 'in', 'the', 'morning', '[SEP]']
Для каждого токенизированного предложения BERT требует входных идентификаторов , последовательности целых чисел, идентифицирующих каждый входной токен по его индексу. число в словаре токенизатора BERT.
Умная задача моделирования языка BERT маскирует 15% слов во входных данных и просит модель предсказать пропущенное слово. Чтобы BERT лучше справлялся с отношениями между несколькими предложениями, процесс предварительного обучения также включал дополнительную задачу: учитывая два предложения (A и B), может ли B быть предложением, следующим за A? Поэтому нам нужно сообщить BERT, какую задачу мы решаем, используя концепцию маски внимания и маски сегмента. В нашем случае все слова в запросе будут предсказаны, и у нас нет нескольких предложений на запрос.Мы определяем маску ниже.
Теперь пришло время создать все тензоры и итераторы, необходимые для точной настройки BERT с использованием наших данных.
Наконец, пришло время настроить модель BERT так, чтобы она выводила класс намерения с учетом строки пользовательского запроса. Для этой цели мы используем BertForSequenceClassification , которая представляет собой обычную модель BERT с добавленным одним линейным слоем наверху для классификации. Ниже мы отображаем краткое описание модели. Сводка кодировщика отображается только один раз.Одно и то же резюме обычно повторяется 12 раз. Для простоты мы отображаем только 1 из них. Вначале мы видим уровень BertEmbedding , за которым следует архитектура преобразователя для каждого уровня кодера: BertAttention , BertIntermediate , BertOutput . В конце у нас есть слой Classifier .
По мере того, как мы вводим входные данные, вся предварительно обученная модель BERT и дополнительный необученный уровень классификации обучаются нашей конкретной задаче.Обучение классификатору относительно недорогое. Нижние слои уже имеют отличное представление английских слов, и нам действительно нужно обучить только верхний слой, с небольшой настройкой, происходящей на нижних уровнях, чтобы соответствовать нашей задаче. Это вариант трансферного обучения.
BERT точно настроен для задачи классификации намерений для понимания естественного языка.График потери обучения из переменной train_loss_set выглядит потрясающе. Весь цикл тренировки занял менее 10 минут.
Теперь момент истины. BERT переоснащен? Или она лучше, чем наша предыдущая сеть LSTM? Теперь мы загружаем тестовый набор данных и подготавливаем входные данные так же, как мы это делали с обучающим набором. Затем мы создаем тензоры и запускаем модель в наборе данных в режиме оценки.
С помощью BERT мы можем получить хорошую оценку (95,93%) за задачу классификации по намерениям. Это демонстрирует, что с предварительно обученной моделью BERT можно быстро и эффективно создать высококачественную модель с минимальными усилиями и временем обучения с использованием интерфейса PyTorch.
В этой статье я продемонстрировал, как загрузить предварительно обученную модель BERT в блокнот PyTorch и настроить ее на собственном наборе данных для решения конкретной задачи. Внимание имеет значение при работе с задачами понимания естественного языка. Как мы успешно показали, в сочетании с мощным встраиванием слов из Transformer классификатор намерений может значительно улучшить его производительность.
В моей новой статье представлен проверенный на практике код PyTorch для ответов на вопросы с помощью BERT, тонко настроенного на наборе данных SQuAD.
Эта область открывает широкие двери для будущей работы, особенно потому, что понимание естественного языка лежит в основе нескольких технологий, включая разговорный ИИ (чат-боты, личные помощники) и грядущую расширенную аналитику . организации столкнутся очень скоро. Понимание естественного языка оказывает влияние на традиционные аналитические и бизнес-аналитики, поскольку руководители быстро внедряют интеллектуальный поиск информации с помощью текстовых запросов и описаний данных вместо панелей мониторинга со сложными диаграммами.
Спасибо, что прочитали от меня больше.
Практическое руководство по классификации текста с моделями трансформаторов (XLNet, BERT, XLM, RoBERTa) | автор: Thilina Rajapakse
Пожалуйста, подумайте об использовании библиотеки Simple Transformers, поскольку она проста в использовании, многофункциональна и регулярно обновляется. Статья по-прежнему является ссылкой на модели BERT и, вероятно, поможет понять, как работает BERT. Тем не менее, Simple Transformers предлагает гораздо больше функций, гораздо более простые варианты настройки, при этом они быстрые и простые в использовании! Ссылки ниже должны помочь вам быстро приступить к работе.
- Двоичная классификация
- Мультиклассовая классификация
- Многоклассовая классификация
- Распознавание именованных сущностей (теги части речи)
- Ответ на вопрос
- Задачи и регрессия пары предложений
- Модель разговорного языка Тонкая настройка
- ELECTRA и обучение языковой модели с нуля
- Визуализация обучения модели
Библиотека Pytorch-Transformers (теперь Transformers) значительно изменилась с момента написания этой статьи.Я рекомендую использовать SimpleTransformers , поскольку он обновляется вместе с библиотекой Transformers и значительно более удобен для пользователя. Хотя идеи и концепции, изложенные в этой статье, остаются в силе, код и репозиторий Github больше не поддерживаются активно.
- Тонкая настройка языковой модели
- Обучение ELECTRA и языковой модели с нуля
- Визуализация обучения модели
Я настоятельно рекомендую клонировать репозиторий Github для этой статьи и запускать код, следуя инструкциям .Это должно помочь вам лучше понять как руководство, так и код. Чтение отличное, но кодирование лучше р. 😉
Особая благодарность Hugging Face за их библиотеку Pytorch-Transformers за то, что с моделями трансформаторов легко и весело играть!
Модели-трансформеры покорили мир обработки естественного языка, преобразив (извините!) Эту область стремительно. Новые, большие и лучшие модели появляются почти каждый месяц, устанавливая новые стандарты производительности для самых разных задач.
Этот пост задуман как простое руководство по использованию этих замечательных моделей для задач классификации текста. Таким образом, я не буду говорить о теории, лежащей в основе сетей, или о том, как они работают под капотом. Если вы хотите погрузиться в подробности Трансформеров, я рекомендую вам ознакомиться с иллюстрированными руководствами Джея Аламмара.
Это также служит обновлением моего более раннего руководства по использованию BERT для классификации двоичного текста. Я буду использовать тот же набор данных (Yelp Reviews), который использовал в прошлый раз, чтобы не загружать новый набор данных, потому что я ленив и у меня ужасный интернет.Мотивация обновления объясняется несколькими причинами, в том числе обновлением библиотеки HuggingFace, которую я использовал для предыдущего руководства, а также выпуском нескольких новых моделей Transformer, которым удалось сбить BERT с его позиции.
Установив фон, давайте посмотрим, что мы будем делать.
- Настройка среды разработки с помощью библиотеки Pytorch-Transformers от HuggingFace.
- Преобразование наборов данных .csv в .Формат tsv , используемый библиотекой HuggingFace.
- Настройка предварительно обученных моделей.
- Преобразование данных в объекты.
- Точная настройка моделей.
- Оценка.
Я буду использовать два Jupyter Notebook, один для подготовки данных, а другой для обучения и оценки.
Давайте настроим среду.
- Настоятельно рекомендуется использовать виртуальную среду при установке и работе с различными библиотеками Python. Мой личный фаворит — Anaconda, но вы можете использовать все, что захотите.
conda create -n transformers python pytorch pandas tqdm jupyterОбратите внимание, что в руководстве могут использоваться дополнительные пакеты которые здесь не установлены. Если вы столкнетесь с отсутствующими пакетами, просто установите их через conda или pip.
conda activate transformers
conda install -c anaconda scikit-learn
pip install pytorch-transformers
pip install tensorboardX
- Пользователи Linux могут использовать здесь сценарий оболочки для загрузки и извлечения набора данных Yelp Reviews Polarity.Другие могут загрузить его вручную здесь, на fast.ai. Также прямая ссылка для скачивания.
Я поместил файлыtrain.csvиtest.csvв каталог с именемdata.
/ data /
Пора подготовить данные для моделей трансформаторов.
Большинство онлайн-наборов данных обычно имеют формат .csv . Согласно норме, набор данных Yelp содержит два файла csv, , train.csv и test.csv .
Начиная нашу первую записную книжку (подготовка данных), давайте загрузим файлы csv с помощью Pandas.
Однако используемые здесь ярлыки нарушают норму, будучи 1 и 2 вместо обычных 0 и 1. Я полностью за небольшой бунт, но это меня только отталкивает. Давайте исправим это так, чтобы метки были 0 и 1, что указывает на плохой и хороший отзыв соответственно.
Нам нужно сделать последнюю часть ретуши, прежде чем наши данные будут готовы для моделей Pytorch-Transformer.Данные должны быть в формате tsv , с четырьмя столбцами и без заголовка.
- guid: идентификатор строки.
- метка: метка строки (должна быть целым числом).
- альфа: столбец с одинаковой буквой для всех строк. Не используется в классификации, но все же необходим.
- текст: текст для строки.
Итак, давайте упорядочим данные и сохраним их в формате tsv .
Это знаменует конец Блокнота для подготовки данных, и мы продолжим работу с Блокнотом для обучения из следующего раздела.
От текста к функциям.
Прежде чем мы сможем начать собственное обучение, нам нужно преобразовать наши данные из текста в числовые значения, которые можно будет передать в нейронные сети. В случае моделей Transformer данные будут представлены как объекты InputFeature .
Чтобы подготовить наши данные к Transformer, мы будем использовать классы и функции из файла utils.py . (Соберитесь, стена кода приходит!)
Давайте посмотрим на важные части.
Класс InputExample представляет один образец нашего набора данных;
-
guid: уникальный идентификатор -
text_a: Наш фактический текст -
text_b: Не используется в классификации -
label: Метка образца
Data andProcessor Классы используются для чтения данных из файлов tsv и преобразования их в InputExamples .
Класс InputFeature представляет чистые числовые данные, которые могут быть переданы в преобразователь.
Три функции convert_example_to_feature , convert_examples_to_features , _truncate_seq_pair используются для преобразования InputExamples в InputFeatures , которые, наконец, будут отправлены в модель Transformer.
Процесс преобразования включает токенизацию и преобразование всех предложений в заданную длину последовательности (усечение более длинных последовательностей и заполнение более коротких последовательностей).Во время токенизации каждое слово в предложении разбивается на все меньшие и меньшие токены (части слова), пока все токены в наборе данных не будут распознаны преобразователем.
В качестве надуманного примера предположим, что у нас есть слово , понимающее . Используемый нами трансформатор не имеет токена для , понимающего , но у него есть отдельные токены для , понимающего и ing. Тогда слово , понимающее , будет разбито на токены понять и ing. Длина последовательности — это количество таких токенов в последовательности.
Функция convert_example_to_feature принимает один образец данных и преобразует его в элемент ввода . Функция convert_examples_to_features принимает список примеров и возвращает список из InputFeatures с помощью функции convert_example_to_feature . Причина наличия двух отдельных функций состоит в том, чтобы позволить нам использовать многопроцессорность в процессе преобразования.По умолчанию я установил счетчик процессов на cpu_count () - 2 , но вы можете изменить его, передав значение параметра process_count в функции convert_examples_to_features .
Теперь мы можем перейти к нашей записной книжке для тренировок и импортировать материалы, которые мы будем использовать, и настроить параметры обучения.
Внимательно просмотрите словарь args и обратите внимание на все различные параметры, которые вы можете настроить для обучения. В моем случае я использую тренировку fp16, чтобы уменьшить использование памяти и ускорить тренировку.Если у вас не установлена Nvidia Apex, вам придется отключить fp16, установив для него значение False.
В этом руководстве я использую модель XL-Net с длиной последовательности 128. Полный список доступных моделей см. В репозитории Github .
Теперь мы готовы загрузить нашу модель для обучения.
Самая крутая вещь в библиотеке Pytorch-Transformers заключается в том, что вы можете использовать любой из MODEL_CLASSES выше, просто изменив model_type и model_name в словаре аргументов.Процесс точной настройки и оценки в основном одинаков для всех моделей. Приветствую HuggingFace!
Далее у нас есть функции, определяющие, как загружать данные, обучать модель и оценивать модель.
Наконец, у нас есть все готово для токенизации наших данных и обучения нашей модели.
Обучение.
Отсюда должно быть довольно просто.
Это преобразует данные в функции и запустит процесс обучения. Преобразованные функции будут автоматически кэшированы, и вы сможете повторно использовать их позже, если захотите провести тот же эксперимент.Однако, если вы измените что-то вроде max_seq_length , вам нужно будет повторно обработать данные. То же самое касается изменения используемой модели. Чтобы повторно обработать данные, просто установите reprocess_input_data на True в словаре args .
Для сравнения, этому набору данных потребовалось около 3 часов для обучения на моем RTX 2080.
После завершения обучения мы можем все сохранить.
Оценка.
Оценить тоже довольно просто.
Без какой-либо настройки параметров и с одной эпохой обучения мои результаты следующие.
ИНФОРМАЦИЯ: __ main __: ***** Результаты оценки *****
ИНФОРМАЦИЯ: __ main__: fn = 1238
ИНФОРМАЦИЯ: __ main__: fp = 809
ИНФОРМАЦИЯ: __ main__: mcc = 0.89247291726
ИНФОРМАЦИЯ: __ main__: tn = 18191
ИНФОРМАЦИЯ: __ main__: tp = 17762
Не так уж и плохо!
Модели Transformer продемонстрировали невероятное мастерство в решении широкого круга задач обработки естественного языка. Здесь мы рассмотрели, как их можно использовать для одной из наиболее распространенных задач — классификации последовательностей.
Библиотека Pytorch-Transformers от HuggingFace позволяет почти тривиально использовать мощь этих гигантских моделей!
- При работе с собственными наборами данных я рекомендую отредактировать записную книжку
data_prep.ipynb, чтобы сохранить файлы данных как файлыtsv. В большинстве случаев вы сможете запустить все, просто убедившись, что правильные столбцы, содержащие текст и метки , переданы в конструкторыtrain_dfиdev_df.Вы также можете определить свой собственный класс, который наследуется от классаDataProcessorв файлеutils.py, но я считаю, что первый подход проще. - Пожалуйста, используйте репозиторий Github вместо копирования и вставки из сообщения здесь. Любые исправления или дополнительные функции будут добавлены в репозиторий Github и вряд ли будут добавлены сюда, если это не критическое изменение. Код встроен в Medium с помощью Gists, и поэтому они не синхронизируются автоматически с кодом репо.
- Если вам нужна поддержка или вы обнаружили ошибку, открытие проблемы в репозитории Github, вероятно, приведет к более быстрому ответу, чем комментарии к этой статье. Здесь легко пропустить комментарии, а отсутствие цепочек комментариев / чатов затрудняет отслеживание. В качестве бонуса другие люди, борющиеся с той же проблемой, вероятно, смогут найти ответ легче, если он будет на Github, а не на среднем ответе.
Трансформаторы для сегментации медицинских изображений
TransUNet, основанная на трансформаторах платформа U-Net, обеспечивает высочайшую производительность в приложениях для сегментации медицинских изображений.U-Net, U-образная архитектура сверточной нейронной сети, сегодня становится стандартом, добившись многочисленных успехов в задачах сегментации медицинских изображений. U-Net имеет симметричную сеть глубокого кодировщика-декодера с пропускаемыми соединениями для улучшения сохранения деталей. U-Net обладает отличной репрезентативной способностью, но имеет плохую дальнодействующую связь из-за внутренней локальности операций свертки. Задачи сегментации медицинских изображений имеют общую проблему различий в текстуре, форме и размере сегментов. Поэтому U-Net с механизмом самовнимания дает неплохие результаты при сегментации медицинских изображений.С другой стороны, Transformers считаются архитектурой, альтернативной U-Nets, которая полагается только на механизмы внимания. Трансформаторы хороши в моделировании глобального контекста, демонстрируя превосходную переносимость для последующих задач в рамках крупномасштабного предварительного обучения. Трансформаторы демонстрируют исключительную производительность в различных задачах машинного обучения, включая обработку естественного языка и распознавание изображений. Однако трансформеры сосредотачиваются исключительно на глобальном контексте, но не могут получить подробную информацию о локализации.Это приводит к функциям с низким разрешением и, как следствие, к потере некоторой ценной информации.
Зарегистрируйтесь в AWS ML Friday и узнайте, как сделать карьеру в области науки о данных.
Предлагается множество расширений или вариаций U-сетей или трансформаторов для улучшения характеристик моделей. TransUNet был представлен Цзянэн Ченом, Юнъи Лу, Цихан Ю, Сяндэ Луо, Эхсаном Адели, Ян Ван, Ле Лу, Аланом Л. Юилле и Юинь Чжоу как гибридная версия U-Net и Трансформеров, воспользовавшись способностями обе архитектуры.TransUNet может собирать подробную информацию о локализации на всех этапах сети, сохраняя при этом возможность передачи контекста на большие расстояния внутри сети. TransUNet дает лучшие результаты по сравнению с моделями самовнимания, основанными на CNN. Он построен на основе Vision Transformer (ViT), современного метода классификации ImageNet. TransUNet демонстрирует превосходные, а также современные характеристики в таких приложениях, как многоорганная сегментация и сегментация сердца.
Архитектура TransUNet FrameworkБлок трансформатора каркаса состоит из 12 слоев Transformer. Один уровень Transformer структуры TransUNet состоит из стека уровня нормализации, слоев множественного выравнивания последовательностей (MSA), уровня нормализации и многослойного персептрона.
Входные изображения поступают в блок CNN, где объекты извлекаются на разных уровнях глубины на разных уровнях. Этот блок CNN действует как кодирующая часть фреймворка.Линейная проекция извлеченных функций подается в блок Transformer для получения глобального контекста функций. Декодерная часть структуры создается путем подачи выходных сигналов блока трансформатора и пропускания соединений от кодирующей части. Выходной сигнал декодера подается в головку сегментации, где получается сегментированная версия исходного изображения.
Коэффициент подобия игральных костей для соединений с пропуском 0, 1 и 3 пропускаУстановлено, что 3-пропускаемые соединения являются лучшими среди 0, 1 или 3 числа пропущенных соединений, что дает самый высокий средний коэффициент подобия игральных костей .Лучшая версия фреймворка TransUNet имеет 3-skip-соединения между кодировщиком и частями декодера.
Реализация TransUNet
на PythonОбщедоступные наборы данных для обучения и / или тестирования фреймворка доступны в облачном хранилище Google в формате Numpy. Среди различных доступных наборов данных мы выполняем реализацию здесь с использованием набора данных R50 + ViT-B_16. Ниже приведены шаги по реализации TransUNet в среде Python.
Шаг-1:
Набор данныхможно загрузить на локальный компьютер с помощью следующей команды.Создается новый каталог для хранения набора данных, чтобы его можно было идентифицировать с помощью предварительно обученной модели.
%% bash wget https://storage.googleapis.com/vit_models/imagenet21k/R50%2BViT-B_16.npz && mkdir -p ../model/vit_checkpoint/imagenet21k && мв R50 + ViT-B_16.npz ../model/vit_checkpoint/imagenet21k/R50%2BViT-B_16.npz
Шаг-2:
Предварительно обученный TransUNet можно импортировать на локальный компьютер с помощью команды
. ! Git clone https: // github.com / Beckschen / TransUNet.git
Выход:
Необходимые файлы, коды Python для предварительно обученных весов, обучения, тестирования и наборы данных загружаются из соответствующего репозитория github.
Наличие файлов в каталоге можно проверить с помощью команды
%% bash cd TransUNet ls -p
Выход:
Шаг-3:
Необходимые библиотеки и пакеты можно установить на локальный компьютер, запустив файл requirements.txt, доступный вместе с загруженными файлами git.Мы должны убедиться, что среда выполнения CUDA GPU включена. В среде ноутбука, такой как colab или Jupyter, CUDA GPU можно включить с помощью параметра меню Runtime.
%% bash cd TransUNet pip install -r requirements.txt
Можно отметить, что текущая реализация работает на платформе PyTorch.
Шаг-4:
МодельTransUNet можно воссоздать, а веса можно восстановить из предварительно обученной модели с помощью следующей команды. Можно отметить, что эта команда предназначена для набора данных R50-ViT-B_16.Для другого набора данных команду можно соответствующим образом изменить.
Смотрите также%% bash cd TransUNet / CUDA_VISIBLE_DEVICES = 0 python train.py --dataset Synapse --vit_name R50-ViT-B_16
В зависимости от объема памяти устройства размер пакета может быть уменьшен до 12 или 6 для экономии памяти. Однако переменная base_lr в коде должна быть линейно уменьшена, и оба размера пакета могут достичь одинаковой производительности.
Шаг 5:
После обучения модель можно протестировать с подходящим набором данных с помощью следующей команды.Здесь тестирование проводится с набором данных Synapse, как и в исходной исследовательской работе.
%% bash cd TransUNet / python test.py --dataset Synapse --vit_name R50-ViT-B_16
Если пользователь заинтересован в тестировании модели со своим собственным набором данных, данные должны быть сохранены в каталоге «набор данных» в формате Numpy. Трехмерные изображения должны быть обрезаны в пределах [-125, 275], нормализованы до [0, 1]. 2D-срезы следует извлекать из 3D-объема для учебных случаев, сохраняя 3D-объем в формате h5 для тестовых случаев.
Наличие набора данных в нужном каталоге может быть подтверждено с помощью команды «tree»
%% bash дерево установки sudo apt-get дерево
Выход:
Производительность TransUNet
Структура TransUNet оценивается с использованием набора данных многоорганной сегментации Synapse. Этот набор данных состоит из компьютерной томографии брюшной полости с аннотациями 8 органов брюшной полости, а именно аорты, желчного пузыря, левой почки, правой почки, печени, поджелудочной железы, селезенки и желудка. Для обозначения сегментов наземные изображения снабжены цветными аннотациями.TransUNet сегментирует данное тестовое изображение с относительно большим средним коэффициентом сходства игральных костей (DSC), чем любой существующий уровень техники. Среднее расстояние Хаусдорфа (HD), мера неправильной сегментации, минимально в методе TransUNet, чем в других существующих методах.
Качественное сравнение TransUNet с существующими современными методами.TransUNet превосходит существующие современные технологии, такие как полностью сверточные нейронные сети для объемной сегментации медицинских изображений (V-Net), доменное адаптивное реляционное мышление (DARR), сверточные сети для сегментации биомедицинских изображений (U-Net), и сети с ограниченным вниманием (AttnUNet) с точки зрения среднего коэффициента сходства игральных костей и среднего расстояния Хаусдорфа.
Примечание: изображения, отличные от выходных кодов, получены из оригинальной исследовательской работы TransUNet
.Дополнительная литература о TransUNet и ссылки:
Присоединяйтесь к нашей группе Telegram. Станьте частью интересного онлайн-сообщества. Присоединиться здесь.
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и актуальные предложения, поделившись своей электронной почтой.Сантос | Телетраан I: Трансформеры вики
Сантос
Сантос
Род занятий
Верховный главнокомандующий ТРФ (ранее)
солдат в У.С. Армия
Сантос — верховный лидер и главный командующий Сил реакции Трансформеров, или сокращенно TRF, международной военной организации с правительственным составом, основной целью которой является уничтожение всех трансформеров на Земле, независимо от фракции, но позже он помогает Автоботы, чтобы спасти Землю.
История
Сантос был оперативником Delta Force, родился в Сан-Паулу, Бразилия, а вырос в Фениксе, штат Аризона.
Встреча с Кейдом Йегером
Сантос впервые был показан, когда Эдмунд Бертон рассказывает о том, как Трансформеры были объявлены незаконными на Земле, и был сформирован TRF, чтобы уничтожить каждого трансформера.Затем Сантос возглавил TRF на миссии в Чикаго, когда дроны обнаружили там Трансформеров, в том числе группу детей, которым было запрещено входить на место. Однако дрон-стражи были уничтожены Изабеллой и ее другом Сквиксом, чтобы защитить детей, и их защищал Кэнопи, автобот, прячущийся в куче обломков. Затем Сантос стал свидетелем встречи с помощью дрона и, полагая, что Кэнопи был десептиконом, причиняющим вред детям, он приказал нанести авиаудар, в результате которого Кэнопи был убит, не зная, что он подвергает Изабеллу и сирот опасности.Сантос и его люди начали выезжать, чтобы «вытащить» детей вместе с Изабеллой, хотя они сбежали с помощью сочувствующего автоботов и беглеца Кейда Йегера, несмотря на протесты Иззи, чтобы помочь Канопи. Сантос и его люди встретили Кейда Йегера и начали его арестовывать, в то время как последний столкнулся с умирающим рыцарем, который дал ему талисман. Затем Сантос сказал Кейду, где он прячет автоботов, но Кейд отказался продать своих друзей. Затем Сантос сказал Кейду, что это было «вторжение» и что они ответственны, когда просыпаются.Тем не менее, Бамблби прибыл и продолжил сборку и убил многих из своих людей, с головой Бамблби, атаковавшей ногу Сантоса, и Кейд захлопнул одну из дверей перед ним, прежде чем Бамблби поддержал его. После того, как его бросили и пощадили, Кейд угрожал убить его, в то время как Сантос велел своим людям убить Кейда, пока не прибыл Уильям Леннокс и не убедил его отступить. Позже прибыл Хаунд и пригрозил им своим пистолетом Гатлинга, что позволило Кейду ослабить противостояние. Когда Сантос сказал Ленноксу, на чьей он стороне, поскольку последний был союзником автоботов, он приказал снайперу TRF запустить устройство слежения по Бамблби.
Охотничий кадет и городская засада
Позже он последовал за командой Десептиконов Мегатрона в другую миссию на свалку Кейда Йегера и преследовал автоботов, когда они выбили его оттуда, чтобы Мегатрон и его команда могли получить талисман Кейда, найденный ранее, у умирающего рыцаря. Затем Кейд, Джимми и Иззи начали скрываться в заброшенном городе после того, как они были вынуждены покинуть свою свалку благодаря устройству слежения, установленному на Бамблби. Конвой TRF начал движение к заброшенному городу, но половина конвоя была уничтожена Гримлоком и Снарлом, остановив их продвижение.Затем Сантос стал свидетелем встречи и, оттолкнув Леннокса, узнав его подозрения, решил взять дело в свои руки и запустил флот мини-дронов, чтобы убить Кейда Йегера. После того, как Мегатрон и Нитро Зевс сбежали, а Натиск, Могавк и Дредбот были убиты Дрифтом, Шмелем и Гримлоком соответственно, мини-дроны начали преследовать Кейда, Джимми и Иззи, когда они бежали в заброшенную церковь. Дроны начали двигаться по Кейду, когда он начал убивать их одного за другим из своего пистолета.Сантос, наблюдая за событиями в прямом эфире на камеру, назвал Кейда «мертвым человеком», когда дроны пытались убить его, начав ненавидеть его из-за его многочисленных побегов и предположительно разгневанный тем, что его люди были убиты. В последовавшем за этим хаосе Джимми, понимая, что дроны выслеживают цель только с помощью распознавания лиц (это Кейд Йегер заклеймил беглецом), начал обманывать мини-дрон, чтобы защитить Кейда, и вместо того, чтобы убивать его, запустил. мешок с фасолью на него, в то время как Кейд уничтожил мини-дрон, чтобы отвлечься.Позже Кейд столкнулся на лифте с Когманом, которого послал Эдмунд Бертон, так как он был выбран в качестве «последнего рыцаря», но дрон оттолкнул его с дороги и уничтожил несколько оставшихся дронов, прежде чем уничтожить дрон-мать. оставшиеся два были сняты прицелом.
В поисках посоха
Когда британские силы TRF, лондонская полиция и МИ-6 вошли в особняк Эдмунда Бертона, чтобы выследить Кейда, Сантос и Леннокс прибыли в Пятый флот ВМС США в Англии, чтобы следить за ситуацией на своих британских коллегах.Когда он потерпел неудачу, Леннокс и Сантос организовали отряд морских котиков и солдат TRF для преследования HMS Alliance, который возглавляли Кейд и Вивиан Уэмбли. Прибыв на древний кибертронский корабль, подводная лодка Сантоса была вынуждена использовать для входа узкую опасную трубу после того, как ворота закрылись за Кейдом. Ему удалось пробраться к рыцарю, который угрожал Кейду и Вивиан. Затем он попытался убедить Вивиан отдать Посох Мерлина, только для того, чтобы она перевернула столы, когда она показала, что она единственная, кто может его использовать.Однако их прервали другие рыцари, которые убили несколько морских котиков, прежде чем Оптимус Прайм, которому промыли мозги, уничтожил рыцарей и убедил Вивиан передать посох. Сантос попытался выстрелить в Оптимуса, но отразил выстрелы и начал противостоять Бамблби.
Последнее противостояние
Он встретился с остальными солдатами TRF, когда корабль оторвался от поверхности океана, и им были предоставлены скопы, чтобы добраться до камеры зажигания после посадки на Корабль Рыцарей, который автоботы использовали в качестве основного транспорта.Он сел в ту же «Скопу», что и Леннокс, Кейд и Вивиан (и, не зная, Изабелла и Сквикс), и поговорил с Кейдом. Наконец, поняв, что его вера в то, что все кибертронцы являются врагами, была большой трагической ошибкой, Сантос и его солдаты сняли значки TRF со своей формы, бросили их на пол и сломали TRF. Затем бывшие солдаты TRF, Сантос и Леннокс достигли камеры и нанесли по ней ядерный удар, понеся множество потерь во время финальной битвы против десептиконов и Квинтессы.После долгой битвы Оптимус произнес речь, прежде чем отправиться обратно в Кибертрон, используя Корабль Рыцаря Автоботов.
Личность
Сантос — лидер TRF и бывший оператор Delta Force, родился в Сан-Паулу, Бразилия, а вырос в Фениксе, Аризона. Как и Гарольд Аттингер, Сантос сначала был безжалостен к Трансформерам, как автоботам, так и десептиконам, поскольку он считал их угрозой для Земли. Но в его глазах то, что он делает, действительно, он приказал нанести авиаудар, чтобы убить Кэнопи, чтобы защитить Изабеллу и других детей, находящихся в запретной зоне Чикаго.Он также безжалостен с людьми, а также со своими собственными солдатами, после того, как Бамблби убил некоторых из своих людей, чтобы спасти Кейда Йегера, а также когда он пытался убить его с помощью дронов TRF после того, как Диноботы уничтожили военный конвой.
Однако, в отличие от Гарольда Аттингера, он искупил себя и изменил свое мнение, когда вступил в союз с Кейдом и автоботами, чтобы спасти мир от Квинтессы и десептиконов. Он и его солдаты вырывают значки TRF со своего костюма, чтобы дать понять, что они больше не представляют угрозы для Кейда и автоботов.
Список литературы
Трансформаторов с нуля | peterbloem.nl
Трансформеры — это очень интересное семейство архитектур машинного обучения. Существует множество хороших руководств (например, [1, 2]), но за последние несколько лет преобразователи в основном стали проще, так что теперь гораздо проще объяснить, как работают современные архитектуры. Этот пост — попытка напрямую объяснить, как работают современные трансформаторы и почему, без некоторого исторического багажа.Я предполагаю базовое понимание нейронных сетей и обратного распространения ошибки.Если вы хотите освежить свои знания, эта лекция познакомит вас с основами нейронных сетей, а эта объяснит, как эти принципы применяются в современных системах глубокого обучения.
Для понимания примеров программирования требуется практическое знание Pytorch, но их также можно пропустить.
Самовнимание
Фундаментальной операцией любой архитектуры трансформатора является операция самовнимания .
Мы объясним, откуда произошло название «самовнимание», позже.А пока не зацикливайтесь на ней.Самовнимание — это операция от последовательности к последовательности: последовательность векторов входит, а последовательность векторов выходит. Назовем входные векторы \ (\ x_1, \ x_2, \ ldots, \ x_t \) и соответствующие выходные векторы \ (\ y_1, \ y_2, \ ldots, \ y_t \). Все векторы имеют размерность \ (k \).
Чтобы создать выходной вектор \ (\ y_ \ rc {i} \), операция самовнимания просто берет средневзвешенное значение по всем входным векторам
$$ \ y_ \ rc {i} = \ sum _ {\ gc {j}} w _ {\ rc {i} \ gc {j}} \ x_ \ gc {j} \ p
$Где \ (\ gc {j} \) индексирует всю последовательность, а весовая сумма равна единице по всей \ (\ gc {j} \).Т \ х_ \ gc {j} \ p
$ Обратите внимание, что \ (\ x_ \ rc {i} \) — это входной вектор в той же позиции, что и текущий выходной вектор \ (\ y_ \ rc {i} \). Для следующего выходного вектора мы получаем совершенно новую серию скалярных произведений и другую взвешенную сумму.Точечное произведение дает нам значение где угодно между отрицательной и положительной бесконечностью, поэтому мы применяем softmax для сопоставления значений с \ ([0, 1] \) и обеспечения их суммирования до 1 по всей последовательности:
$$ w _ {\ rc {i} \ gc {j}} = \ frac {\ text {exp} w ‘_ {\ rc {i} \ gc {j}}} {\ sum_ \ gc {j} \ text {exp } w ‘_ {\ rc {i} \ gc {j}}} \ p
$И это основная операция самовнимания.
Наглядная иллюстрация основного внимания к себе. Обратите внимание, что операция softmax над весами не проиллюстрирована.Для полного трансформатора необходимы еще несколько ингредиентов, о которых мы поговорим позже, но это основная операция. Что еще более важно, это единственная операция во всей архитектуре, которая передает информацию между векторами. Все остальные операции в преобразователе применяются к каждому вектору входной последовательности без взаимодействия между векторами.
Понимание того, почему работает самовнимание
Несмотря на свою простоту, не сразу понятно, почему самовнимание должно работать так хорошо. Чтобы набраться некоторой интуиции, давайте сначала рассмотрим стандартный подход к рекомендации по фильму .
Допустим, вы занимаетесь прокатом фильмов, у вас есть несколько фильмов и несколько пользователей, и вы хотите порекомендовать своим пользователям фильмы, которые, вероятно, им понравятся.
Один из способов сделать это — создать для ваших фильмов вручную функции, например, сколько романтики в фильме и сколько действий, а затем разработать соответствующие функции для ваших пользователей: насколько им нравятся романтические фильмы и насколько им нравятся боевики.Если вы это сделаете, скалярное произведение между двумя векторами признаков даст вам оценку того, насколько хорошо атрибуты фильма соответствуют тому, что нравится пользователю.
Если признаки признака совпадают для пользователя и фильма — фильм романтичен, а пользователь любит романтику или фильм неромантичен , а пользователь ненавидит романтику, — то результирующее скалярное произведение получает положительный термин для этой особенности. Если знаки не совпадают (фильм романтический, а пользователь ненавидит романтику или наоборот), соответствующий термин отрицательный.
Кроме того, величин характеристик показывают, насколько эта функция должна вносить вклад в общий балл: фильм может быть немного романтичным, но не заметным, или пользователь может просто не предпочитать романтику, но быть в значительной степени амбивалентным. .
Конечно, собирать такие характеристики нецелесообразно. Аннотирование базы данных, содержащей миллионы фильмов, очень дорого, а аннотирование пользователей их симпатиями и антипатиями практически невозможно.
Вместо этого мы делаем характеристики фильма и пользовательские характеристики , параметры модели .Затем мы запрашиваем у пользователей небольшое количество фильмов, которые им нравятся, и оптимизируем пользовательские функции и функции фильмов, чтобы их скалярный продукт соответствовал известным лайкам.
Несмотря на то, что мы не сообщаем модели, что должна означать какая-либо из функций, на практике оказывается, что после обучения функции действительно отражают значимую семантику о содержании фильма.
Первые две функции узнали из базовой модели матричной факторизации. Модель не имела доступа к какой-либо информации о содержании фильмов, только о том, какие фильмы понравились пользователям.Обратите внимание, что фильмы расположены от низкого до высокого по горизонтали и от основного до необычного по вертикали. Из [4]. См. Это видео для получения более подробной информации о рекомендательных системах. На данный момент этого достаточно для объяснения того, как скалярное произведение помогает нам представлять объекты и их отношения.Это основной принцип работы с самовниманием. Допустим, мы столкнулись с последовательностью слов. Чтобы применить самовнимание, мы просто присваиваем каждому слову \ (\ bc {t} \) в нашем словаре вектор вложения \ (\ v_ \ bc {t} \) (значения которого мы узнаем).Это так называемый слой встраивания при последовательном моделировании. Получается последовательность слов \ (\ bc {\ text {the}}, \ bc {\ text {cat}}, \ bc {\ text {walks}}, \ bc {\ text {on}}, \ bc {\ text {the} }, \ bc {\ text {street}} \) в векторную последовательность
$$ \ v_ \ bc {\ text {the}}, \ v_ \ bc {\ text {cat}}, \ v_ \ bc {\ text {walks}}, \ v_ \ bc {\ text {on}} , \ v_ \ bc {\ text {the}}, \ v_ \ bc {\ text {street}} \ p
$Если мы скармливаем эту последовательность слою самовнимания, на выходе будет другая последовательность векторов. $$ \ y_ \ bc {\ text {the}}, \ y_ \ bc {\ text {cat}}, \ y_ \ bc {\ text {walks}}, \ y_ \ bc {\ text {on}}, \ y_ \ bc {\ text {the}}, \ y_ \ bc {\ text {улица}} $$ где \ (\ y_ \ bc {\ text {cat}} \) — это взвешенная сумма по всем векторам вложения в первой последовательности, взвешенная их (нормализованным) скалярным произведением с \ (\ v_ \ bc {\ text { Кот}}\).
Поскольку мы изучаем , какими должны быть значения в \ (\ v_ \ bc {t} \), то, как «связаны» два слова, полностью определяется задачей. В большинстве случаев определенный артикль не очень важен для толкования других слов в предложении; следовательно, мы, скорее всего, получим вложение \ (\ v_ \ bc {\ text {the}} \), которое имеет низкое или отрицательное скалярное произведение со всеми другими словами. С другой стороны, чтобы интерпретировать, что означает прогулка в этом предложении, очень полезно определить , кто делает ходьбу.Вероятно, это выражается существительным, поэтому для таких существительных, как кошка, и глаголов, таких как прогулки, мы, вероятно, выучим вложения \ (\ v_ \ bc {\ text {cat}} \) и \ (\ v_ \ bc {\ text {прогулки }} \), которые вместе имеют высокое положительное скалярное произведение.
Это основная интуиция, стоящая за самовниманием. Скалярное произведение выражает, насколько связаны два вектора во входной последовательности, причем «взаимосвязанные» определяются задачей обучения, а выходные векторы представляют собой взвешенные суммы по всей входной последовательности с весами, определяемыми этими скалярными произведениями.
Прежде чем мы продолжим, стоит отметить следующие свойства, которые необычны для операции от последовательности к последовательности:
- Нет параметров (пока). То, что на самом деле делает базовое самовнимание, полностью определяется тем механизмом, который создает входную последовательность. Механизмы апстрима, такие как слой встраивания, стимулируют самовнимание, изучая представления с определенными скалярными произведениями (хотя мы добавим несколько параметров позже).
- Самовнимание видит свой ввод как набор , а не последовательность.Если мы переставим входную последовательность, выходная последовательность будет точно такой же, за исключением перестановки (т.е.самовнимание — это эквивариант перестановки ). Мы несколько смягчим это, когда построим полный трансформатор, но само по себе самовнимание игнорирует последовательный характер ввода.
В Pytorch: основное внимание к себе
То, что я не могу создать, я не понимаю, как сказал Фейнман. Итак, по ходу дела мы построим простой трансформатор.Мы начнем с реализации этой базовой операции самовнимания в Pytorch.
Первое, что мы должны сделать, это придумать, как выразить собственное внимание в умножении матриц. Наивная реализация, которая перебирает все векторы для вычисления весов и выходных данных, была бы слишком медленной.
Мы представим вход, последовательность \ (t \) векторов размерности \ (k \) как матрицу \ (t \) by \ (k \) \ (\ X \). Включение размера мини-пакета \ (b \) дает нам входной тензор размера \ ((b, t, k) \).
Набор всех исходных скалярных произведений \ (w ‘_ {\ rc {i} \ gc {j}} \) образует матрицу, которую мы можем вычислить, просто умножив \ (\ X \) на его транспонирование:
импортная горелка
импортировать torch.nn.functional as F
# предположим, что у нас есть тензор x размера (b, t, k)
х = ...
raw_weights = torch.bmm (x, x.transpose (1, 2))
# - torch.bmm - матричное умножение. Это
# применяет матричное умножение к пакетам
# матриц. Затем, чтобы превратить необработанные веса \ (w ‘_ {\ rc {i} \ gc {j}} \) в положительные значения, сумма которых равна единице, мы применяем построчно softmax:
веса = F.softmax (raw_weights, dim = 2) Наконец, чтобы вычислить выходную последовательность, мы просто умножаем весовую матрицу на \ (\ X \). Это приводит к пакету выходных матриц \ (\ Y \) размером (b, t, k) , строки которых являются взвешенными суммами по строкам \ (\ X \).
y = резак. Bmm (вес, x) Вот и все. Два матричных умножения и одно softmax дают нам основное внимание к себе.
Дополнительные приемы
Фактическое самовнимание, используемое в современных трансформаторах, основано на трех дополнительных приемах.
1) Запросы, ключи и значения
Каждый входной вектор \ (\ x_ \ rc {i} \) используется в операции самовнимания тремя разными способами:
- Он сравнивается со всеми остальными векторами, чтобы установить веса для его собственного вывода \ (\ y_ \ rc {i} \)
- Он сравнивается с любым другим вектором, чтобы установить веса для выходных данных \ (\ gc {j} \) — го вектора \ (\ y_ \ gc {j} \)
- Он используется как часть взвешенной суммы для вычисления каждого выходного вектора после того, как веса были установлены. k} \) со всеми значениями \ (c \).Его евклидова длина равна \ (\ sqrt {k} c \). Следовательно, мы делим величину, на которую увеличение размерности увеличивает длину средних векторов.
3) Многоголовое внимание
Наконец, мы должны учитывать тот факт, что слово может означать разные вещи для разных соседей. Рассмотрим следующий пример. \ (\ bc {\ text {mary}}, \ bc {\ text {give}}, \ bc {\ text {roses}}, \ bc {\ text {to}}, \ bc {\ text {susan} } \) Мы видим, что слово дал по-разному относится к разным частям предложения.Мэри выражает, кто дает, розы выражают то, что дарят, а Сьюзан выражает, кто получает.
За одну операцию самовнимания вся эта информация просто суммируется. Если бы Сьюзен отдала розы Мэри, выходной вектор \ (\ y_ \ bc {\ text {given}} \) был бы таким же, даже если значение изменилось.
Мы можем придать самовниманию большую способность различения, объединив несколько механизмов самовнимания (которые мы будем индексировать с помощью \ (\ bc {r} \)), каждый с разными матрицами \ (\ W_q ^ \ bc {r} \), \ (\ W_k ^ \ bc {r} \), \ (\ W_v ^ \ bc {r} \).\ bc {r} \). Мы объединяем их и передаем через линейное преобразование, чтобы уменьшить размерность до \ (k \).
Эффективное самовнимание с несколькими головами. Самый простой способ понять многоголовое самовнимание — это рассматривать его как небольшое количество копий механизма самовнимания, применяемых параллельно, каждая со своим собственным ключом, значением и преобразованием запроса. Это хорошо работает, но для \ (R \) голов операция самовнимания в \ (R \) раз медленнее.
Оказывается, мы можем съесть свой пирог и съесть его: есть способ реализовать самовнимание с несколькими головами так, чтобы оно было примерно таким же быстрым, как и версия с одной головкой, но мы все равно получаем преимущество в виде другого внимания матрицы параллельно.\ bc {r} \) все \ (32 \ times 32 \).
Для простоты ниже мы опишем реализацию первого, более дорогого метода самовнимания с несколькими головами.
Чтобы подробно понять, как реализована более эффективная, нарезанная на части версия, см. Лекцию, указанную в верхней части сообщения.В Pytorch: полное внимание к себе
Давайте теперь реализуем модуль самовнимания со всеми прибамбасами. Мы упакуем его в модуль Pytorch, чтобы мы могли повторно использовать его позже.\ bc {r} _v \), но на самом деле более эффективно объединить их для всех голов в три одиночные матрицы \ (k \ times hk \), чтобы мы могли вычислить все конкатенированные запросы, ключи и значения в одной матрице. умножение.
# Они вычисляют запросы, ключи и значения для всех # голов (как единый конкатенированный вектор) self.tokeys = nn.Linear (k, k * голов, смещение = False) self.toqueries = nn.Linear (k, k * голов, смещение = False) self.tovalues = nn.Linear (k, k * голов, смещение = False) # Это объединяет выходы разных головок в # один k-вектор себя.unifyheads = nn.Linear (головки * k, k)Теперь мы можем реализовать вычисление самовнимания (функция модуля
вперед). Сначала мы вычисляем запросы, ключи и значения:def вперед (self, x): b, t, k = x.size () h = self.heads запросы = self.toqueries (x) .view (b, t, h, k) ключи = self.tokeys (x) .view (b, t, h, k) значения = self.tovalues (x) .view (b, t, h, k)Выходные данные каждого линейного модуля имеют размер
(b, t, h * k), который мы просто изменяем на(b, t, h, k), даем каждой головке свой размер.Затем нам нужно вычислить скалярные произведения. Это та же операция для каждой головки, поэтому мы складываем головки в размер партии. Это гарантирует, что мы можем использовать
torch.bmm (), как и раньше, и вся коллекция ключей, запросов и значений будет восприниматься как немного больший пакет.Поскольку размер головы и партии не расположены рядом друг с другом, перед изменением формы нам необходимо транспонировать. (Это дорого, но кажется неизбежным.)
# - складывать головки в размер партии keys = ключи.транспонировать (1, 2) .contiguous (). view (b * h, t, k) запросы = query.transpose (1, 2) .contiguous (). view (b * h, t, k) values = values.transpose (1, 2) .contiguous (). view (b * h, t, k)Как и раньше, скалярные произведения могут быть вычислены путем умножения одной матрицы, но теперь между запросами и ключами.
Перед этим, однако, мы перемещаем масштабирование скалярного произведения на \ (\ sqrt {k} \) назад и вместо этого масштабируем ключи и запросы на \ (\ sqrt [4] {k} \) перед их умножением.Это должно сэкономить память для более длинных последовательностей.
запросов = запросов / (k ** (1/4)) keys = ключи / (k ** (1/4)) # - получить скалярное произведение запросов и ключей и масштаб точка = torch.bmm (запросы, keys.transpose (1, 2)) # - точка имеет размер (b * h, t, t), содержащую исходные веса точка = F. softmax (точка, dim = 2) # - точка теперь содержит нормализованные веса по строкамМы применяем собственное внимание к значениям, давая нам результат для каждой головы внимания
# обращаем внимание на значения out = факел.bmm (точка, значения) .view (b, h, t, k)Чтобы объединить головы внимания, мы снова транспонируем, так что размер головы и измерение вложения находятся рядом друг с другом, и меняем форму, чтобы получить конкатенированные векторы размерности \ (kh \). Затем мы пропускаем их через слой
unifyheads, чтобы спроецировать их обратно до размеров \ (k \).# swap h, t back, unify головки out = out.transpose (1, 2) .contiguous (). view (b, t, h * k) вернуть self.unifyheads (уйти)Вот и все: самовнимание с масштабируемым скалярным произведением с несколькими головками.Вы можете увидеть полную реализацию здесь.
Реализацию можно сделать более краткой, используя нотацию einsum (см. Пример здесь).Корпус
трансформаторыТрансформатор — это не просто слой самовнимания, это архитектура . Не совсем понятно, что можно считать трансформатором, а что нет, но здесь мы будем использовать следующее определение:
Любая архитектура, предназначенная для обработки связанного набора единиц — например, токенов в последовательности или пикселей в изображении — где единственное взаимодействие между единицами — это самовнимание.
Как и в случае с другими механизмами, такими как свертки, появился более или менее стандартный подход к тому, как выстраивать уровни самовнимания в более крупную сеть. Первый шаг — заключить собственное внимание в блок , который мы можем повторить.
Блок трансформатора
Существует несколько вариантов построения базового трансформаторного блока, но большинство из них имеют примерно такую структуру:
То есть блок применяет последовательно: слой самовнимания, нормализацию уровня, уровень прямой связи (один MLP , применяемый независимо к каждому вектору) и нормализацию другого уровня.Остаточные соединения добавляются вокруг обоих перед нормализацией. Порядок различных компонентов не высечен на камне; важно объединить самовнимание с локальной прямой связью, а также добавить нормализацию и остаточные связи.
Нормализация и остаточные связи — это стандартные приемы, которые помогают глубоким нейронным сетям обучаться быстрее и точнее. Нормализация слоя применяется только к размеру встраивания.Вот как выглядит блок трансформатора в пирорче.
класс TransformerBlock (nn.Module): def __init __ (себя, k, головы): супер () .__ init __ () self.attention = SelfAttention (k, головы = головы) self.norm1 = nn.LayerNorm (k) self.norm2 = nn.LayerNorm (k) self.ff = nn.Sequential ( nn.Linear (k, 4 * k), nn.ReLU (), nn.Linear (4 * k, k)) def вперед (self, x): присутствовал = самовнимание (x) x = self.norm1 (посещал + x) fedforward = self.ff (х) вернуть self.norm2 (fedforward + x)Мы сделали относительно произвольный выбор, сделав скрытый слой прямой связи в 4 раза больше, чем входной и выходной.Меньшие значения также могут работать и экономить память, но они должны быть больше, чем уровни ввода / вывода.
Классификационный трансформатор
Самый простой преобразователь, который мы можем построить, — это классификатор последовательности . Мы будем использовать набор данных классификации настроений IMDb : экземпляры представляют собой обзоры фильмов, токенизированные в последовательности слов, а классификационные метки —
положительныхиотрицательных(указывающих, был ли отзыв о фильме положительным или отрицательным).Сердцем архитектуры будет просто большая цепочка блоков-трансформаторов. Все, что нам нужно сделать, это решить, как скормить ему входные последовательности и как преобразовать окончательную выходную последовательность в единую классификацию.
Полный эксперимент можно найти здесь. В этом сообщении блога мы не будем рассматривать споры о данных. Перейдите по ссылкам в коде, чтобы увидеть, как данные загружаются и подготавливаются.
Результат: создание классификации
Наиболее распространенный способ построения классификатора последовательностей из слоев от последовательности к последовательности — применить объединение глобального среднего к окончательной выходной последовательности и сопоставить результат с вектором класса softmaxed.
Обзор простого преобразователя классификации последовательностей. Выходная последовательность усредняется для получения единственного вектора, представляющего всю последовательность. Этот вектор проецируется вниз до вектора с одним элементом на класс и softmaxed для получения вероятностей.Ввод: с использованием позиций
Мы уже обсуждали принцип встраиваемого слоя. Это то, что мы будем использовать для обозначения слов.
Однако, как мы уже упоминали, мы складываем эквивариантные уровни перестановок, и окончательное глобальное среднее объединение — это перестановка в вариант , поэтому сеть в целом также инвариантна относительно перестановок.Проще говоря: если мы перемешаем слова в предложении, мы получим точно такую же классификацию, какие бы веса мы ни узнали. Ясно, что мы хотим, чтобы наша современная языковая модель имела хотя бы некоторую чувствительность к порядку слов, поэтому это необходимо исправить.
Решение простое: мы создаем второй вектор равной длины, который представляет позицию слова в текущем предложении, и добавляем его к встраиванию слова. k \) для сопоставьте позиции с действительными векторами и позвольте сети выяснить, как интерпретировать эти кодировки.Преимущество состоит в том, что для хорошо выбранной функции сеть должна иметь возможность работать с последовательностями, которые длиннее, чем те, которые она наблюдала во время обучения (вряд ли с ними будет хорошо работать, но, по крайней мере, мы можем проверить). Недостатки в том, что выбор функции кодирования представляет собой сложный гиперпараметр и немного усложняет реализацию.
Для простоты мы будем использовать встраивание позиций в нашей реализации.
Pytorch
Вот полный преобразователь классификации текста в pytorch.
КлассТрансформатор
(nn.Module): def __init __ (себя, k, головы, глубина, seq_length, num_tokens, num_classes): супер () .__ init __ () self.num_tokens = num_tokens self.token_emb = nn.Embedding (num_tokens, k) self.pos_emb = nn.Embedding (seq_length, k) # Последовательность блоков трансформатора, которая выполняет все # тяжелая атлетика tblocks = [] для i в диапазоне (глубина): tblocks.append (TransformerBlock (k = k, головы = головы)) себя.tblocks = nn.Sequential (* tblocks) # Сопоставляет финальную выходную последовательность с логитами классов self.toprobs = nn.Linear (k, num_classes) def вперед (self, x): "" " : param x: A (b, t) тензор целочисленных значений, представляющих слова (в заранее определенном словаре). : return: A (b, c) тензор логарифмических вероятностей над классы (где c - количество классов). "" " # генерировать вложения токенов токены = self.token_emb (x) b, t, k = токены.размер() # генерировать вложения позиций позиции = torch.arange (t) позиции = self.pos_emb (позиции) [Нет,:,:]. expand (b, t, k) x = токены + позиции х = self.tblocks (х) # Средний пул по измерению t и от проекта к классу # вероятности x = self.toprobs (x.mean (dim = 1)) вернуть F.log_softmax (x, dim = 1)На глубине 6, с максимальной длиной последовательности 512, этот преобразователь достигает точности около 85%, конкурируя с результатами моделей RNN, и намного быстрее обучается.Чтобы увидеть реальные возможности трансформеров, близкие к человеческим, нам нужно обучить гораздо более глубокую модель на гораздо большем количестве данных. Подробнее о том, как это сделать, позже.
Преобразователь генерации текста
Следующий трюк, который мы попробуем, — модель с авторегрессией . Мы обучим преобразователь уровня символов , чтобы предсказывать следующий символ в последовательности. Режим тренировок прост (и существует гораздо дольше, чем у трансформаторов). Мы даем модели «последовательность-последовательность» последовательность и просим ее предсказать следующий символ в каждой точке последовательности.Другими словами, целевой вывод — это та же последовательность, сдвинутая на один символ влево:
С RNN это все, что нам нужно сделать, поскольку они не могут смотреть вперед во входную последовательность: выход \ (i \) зависит только от входов с \ (0 \) до \ (i \). С трансформатором вывод зависит от всей входной последовательности, поэтому предсказание следующего символа становится бессмысленно простым, просто извлеките его из ввода.
Чтобы использовать самовнимание в качестве модели авторегрессии, нам нужно убедиться, что оно не может смотреть вперед в последовательности.Мы делаем это, применяя маску к матрице скалярных произведений перед применением softmax. Эта маска отключает все элементы выше диагонали матрицы.
Маскировка собственного внимания, чтобы гарантировать, что элементы могут обращаться только к входным элементам, которые предшествуют им в последовательности. Обратите внимание, что символ умножения немного вводит в заблуждение: мы фактически устанавливаем замаскированные элементы (белые квадраты) на \ (- \ infty \)Поскольку мы хотим, чтобы эти элементы были равны нулю после softmax, мы устанавливаем их в \ (- \ infty \).8 \) символов текста Википедии (включая разметку). Во время обучения мы генерируем пакеты путем случайной выборки подпоследовательностей из данных.
Мы обучаем на последовательностях длиной 256, используя модель из 12 блоков трансформатора и 256 размерностей встраивания. После примерно 24-часового обучения на RTX 2080Ti (около 170K пакетов размером 32) мы позволяем модели генерировать из 256-символьного начального числа: для каждого символа мы загружаем ему предыдущие 256 символов и смотрим, что она предсказывает для следующего. символ (последний выходной вектор).Мы выбираем из этого с температурой 0,5 и переходим к следующему символу.
Результат выглядит так:
1228X Человек и Руссо. Потому что многие его рассказы изначально были опубликованы в давно забытых журналах и журналов существует ряд [[антологий | антологий]] разных подборщиков, каждая из которых содержит различную подборку. Его оригинальные книги считались антология в [[Средние века]], и, вероятно, была одной из самых распространенных в [[Индийский океан]] в [[1 веке]].В результате его смерти Библия была признается как контратака [[Евангелие от Матфея]] (1177–1133), и [[Саксония | Саксы]] [[Остров Матфея]] (1100–1138), третий был темой [[Саксония | Саксонский]] трон и [[Римская империя | Римская]] войска [[Антиохии]] (1145-1148). [[Римская империя | Римляне]] ушли в отставку в [[1148]] и [[1148]] начали крах. [[Саксония | Саксы]] из [[Битвы при Валасандре]] сообщили о
Обратите внимание, что синтаксис тега ссылок Википедии используется правильно, что текст внутри ссылок представляет разумную тематику для ссылок.Самое главное, обратите внимание, что существует грубая тематическая согласованность; сгенерированный текст продолжает тему Библии и Римской империи, используя разные родственные термины в разных местах. Хотя это далеко от производительности такой модели, как GPT-2, преимущества по сравнению с аналогичной моделью RNN уже очевидны: более быстрое обучение (для обучения аналогичной модели RNN потребуется много дней) и лучшая долгосрочная когерентность.
Если вам интересно, битва при Валасандре кажется изобретением сети.На этом этапе модель обеспечивает сжатие 1,343 бита на байт на проверочном наборе, что не так уж далеко от современного уровня 0,93 бита на байт, достигнутого моделью GPT-2 (описанной ниже).
Рекомендации по проектированию
Чтобы понять, почему трансформаторы настроены таким образом, полезно понять основные конструктивные соображения, которые вошли в их состав. Суть преобразователя заключалась в том, чтобы преодолеть проблемы предыдущей современной архитектуры, RNN (обычно LSTM или GRU).В развернутом виде RNN выглядит так:
Самым большим недостатком здесь является повторяющееся подключение. хотя это позволяет информации распространяться по последовательности, это также означает, что мы не можем вычислить ячейку на временном шаге \ (i \), пока мы не вычислим ячейку на временном шаге \ (i — 1 \). Сравните это с одномерной сверткой:
В этой модели каждый выходной вектор может вычисляться параллельно с любым другим выходным вектором. Это делает свертки намного быстрее. Однако недостатком сверток является то, что они сильно ограничены при моделировании дальнодействующих зависимостей .На одном уровне свертки только слова, расположенные ближе друг к другу, чем размер ядра, могут взаимодействовать друг с другом. Для большей зависимости нам нужно сложить много сверток.
Трансформатор — это попытка объединить лучшее из обоих миров. Они могут моделировать зависимости по всему диапазону входной последовательности так же легко, как и для слов, находящихся рядом друг с другом (фактически, без векторов положения они даже не заметят разницы). И все же здесь нет повторяющихся соединений, поэтому вся модель может быть вычислена очень эффективным способом с прямой связью.
Остальная часть конструкции трансформатора основана в первую очередь на одном соображении: глубина. Большинство вариантов вытекает из желания обучить большие стопки трансформаторных блоков. Обратите внимание, например, что в трансформаторе есть только два места, где возникают нелинейности: softmax в самовнимании и ReLU в слое прямой связи. Остальная часть модели полностью состоит из линейных преобразований, которые отлично сохраняют градиент.
Я полагаю, что нормализация слоя также является нелинейной, но это одна из нелинейностей, которая на самом деле помогает сохранить стабильность градиента, когда он распространяется обратно по сети.Исторический багаж
Если вы читали другие введения в трансформаторы, вы могли заметить, что они содержат некоторые биты, которые я пропустил. Я думаю, что это не обязательно для понимания современных трансформаторов. Однако они помогают понять некоторую терминологию и некоторые записи о современных трансформаторах. Вот самые важные.
Почему это называется само-
внимание ?До того, как было впервые представлено самовнимание, модели последовательностей в основном состояли из повторяющихся сетей или сверток, сложенных вместе.В какой-то момент было обнаружено, что этим моделям можно помочь, добавив механизмов внимания : вместо того, чтобы подавать выходную последовательность предыдущего уровня непосредственно на вход следующего, был введен промежуточный механизм, который решал, какие элементы вход был актуален для конкретного слова выхода.
Общий механизм был следующим. Мы называем вход значений . Некоторые (обучаемые) механизмы назначают ключ каждому значению.Затем каждому выходу какой-то другой механизм назначает запрос .
Эти имена происходят от структуры данных хранилища «ключ-значение». В этом случае мы ожидаем, что только один элемент в нашем магазине будет иметь ключ, соответствующий запросу, который возвращается при выполнении запроса. Внимание — смягченная версия этого: каждые ключей в хранилище в некоторой степени соответствует запросу. Все возвращаются, и мы берем сумму, взвешенную по степени соответствия каждого ключа запросу.
Великий прорыв в самовнимании заключался в том, что внимание само по себе является достаточно сильным механизмом, чтобы осуществить все обучение.Все, что вам нужно, как говорят авторы, — это внимание. Ключ, запрос и значение — это одни и те же векторы (с небольшими линейными преобразованиями). Они заботятся о себе , и накопление такого самовнимания обеспечивает достаточную нелинейность и репрезентативную силу для изучения очень сложных функций.
Оригинальный преобразователь: кодировщики и декодеры
Но авторы не обошлись без всей сложности современного последовательного моделирования. Стандартной структурой моделей от последовательности к последовательности в те дни была архитектура кодировщика-декодера с принуждением учителя.
Кодер берет входную последовательность и отображает ее в единственный скрытый вектор , представляющий всю последовательность. Затем этот вектор передается в декодер , который распаковывает его в желаемую целевую последовательность (например, то же предложение на другом языке).
Принудительное принуждение учителя относится к технике, которая также разрешает доступ декодеру к входному предложению, но с авторегрессией. То есть декодер генерирует выходное предложение слово в слово, основываясь как на скрытом векторе, так и на словах, которые он уже сгенерировал.Это снимает некоторую нагрузку со скрытого представления: декодер может использовать дословную выборку, чтобы позаботиться о низкоуровневой структуре, такой как синтаксис и грамматика, и использовать скрытый вектор для захвата семантической структуры более высокого уровня. Двойное декодирование с одним и тем же скрытым вектором в идеале даст вам два разных предложения с одинаковым значением.
В более поздних преобразователях, таких как BERT и GPT-2, полностью отказались от конфигурации кодировщика / декодера. Было обнаружено, что простого набора трансформаторных блоков достаточно для достижения современного уровня во многих задачах, основанных на последовательности.
Иногда это называют преобразователем только для декодера (для модели авторегрессии) или преобразователем только для кодировщика (для модели без маскирования).Современные трансформаторы
Вот небольшая подборка некоторых современных трансформаторов и их наиболее характерных деталей.
BERT
BERT была одной из первых моделей, показавших, что трансформеры могут достичь производительности человеческого уровня в различных языковых задачах: ответы на вопросы, классификация настроений или определение того, следуют ли два предложения друг за другом естественным образом.
BERT состоит из простого стека трансформаторных блоков того типа, который мы описали выше. Этот стек представляет собой предварительно обученных в большом корпусе общей предметной области, состоящем из 800 миллионов слов из английских книг (современные работы, от неопубликованных авторов) и 2,5 миллиарда слов текста из статей в Википедии на английском языке (без разметки).
Предварительная подготовка осуществляется с помощью двух задач:
- Маскирование
- Определенное количество слов во входной последовательности: замаскировано, заменено случайным словом или сохранено как есть.Затем модель просят предсказать для этих слов, какими были исходные слова. Обратите внимание, что модели не требуется предсказывать все очищенное предложение, а только измененные слова. Поскольку модель не знает, о каких словах ее спросят, она изучает представление для каждого слова в последовательности.
- Следующая классификация последовательностей
- Отбираются две последовательности примерно из 256 слов, которые либо (а) следуют друг за другом непосредственно в корпусе, либо (б) обе взяты из случайных мест.Затем модель должна предсказать, имеет ли место a или b.
BERT использует токенизацию WordPiece, которая находится где-то между последовательностями на уровне слов и на уровне символов. Он разбивает такие слова, как «подход к жетонам» и «## ing». Это позволяет модели делать некоторые выводы на основе структуры слова: два глагола, оканчивающиеся на -ing, имеют схожие грамматические функции, а два глагола, начинающиеся с walk-, имеют схожую семантическую функцию.
К входу добавляется специальный токен
.Выходной вектор, соответствующий этому токену, используется в качестве представления предложения в задачах классификации последовательностей, таких как классификация следующего предложения (в отличие от глобального среднего пула по всем векторам, которые мы использовали в нашей модели классификации выше). После предварительного обучения после тела блоков преобразователей помещается один слой, специфичный для конкретной задачи, который сопоставляет представление общего назначения с выходными данными конкретной задачи. Для задач классификации это просто сопоставляет первый выходной токен с вероятностями softmax по классам.Для более сложных задач последний слой от последовательности к последовательности разработан специально для этой задачи.
Затем вся модель повторно обучается для точной настройки модели под конкретную задачу.
В эксперименте по абляции авторы показывают, что наибольшее улучшение по сравнению с предыдущими моделями связано с двунаправленным характером BERT. То есть в предыдущих моделях, таких как GPT, использовалась авторегрессивная маска, которая позволяла обращать внимание только на предыдущие токены. Тот факт, что в BERT все внимание сосредоточено на всей последовательности, является основной причиной улучшения производительности.
Вот почему B в BERT означает «двунаправленный».Самая большая модель BERT использует 24 блока трансформатора, размер встраивания 1024 и 16 головок внимания, в результате чего получается 340 миллионов параметров.
GPT-2
GPT -2 — первая модель-трансформер, которая попала в массовые новости после спорного решения OpenAI не выпускать полную модель.
Причина заключалась в том, что GPT-2 мог генерировать достаточно правдоподобный текст, чтобы масштабные кампании фейковых новостей, подобные тем, что были на президентских выборах в США в 2016 году, фактически превратились в работу одного человека.Первым трюком, который использовали авторы GPT-2, было создание нового высококачественного набора данных. В то время как BERT использовал высококачественные данные, их источники (с любовью написанные книги и хорошо отредактированные статьи в Википедии) имели определенное отсутствие разнообразия в стиле написания. Чтобы собрать более разнообразные данные без ущерба для качества, авторы использовали ссылки, размещенные в социальной сети Reddit , чтобы собрать большую коллекцию письменных материалов с определенным минимальным уровнем социальной поддержки (выраженным на Reddit как карма ).
GPT2 — это, по сути, модель поколения , поэтому она использует замаскированное самовнимание, как мы это делали в нашей модели выше. Он использует кодировку пар байтов для токенизации языка, которая, как и кодировка WordPiece, разбивает слова на токены, которые немного больше отдельных символов, но меньше целых слов.
GPT2 построен во многом так же, как наша модель генерации текста выше, только с небольшими различиями в порядке слоев и добавленными трюками для обучения на большей глубине.Самая большая модель использует 48 блоков трансформаторов, длину последовательности 1024 и размер встраивания 1600, что дает 1,5B параметров.
Они показывают современное исполнение многих задач. В задаче сжатия Википедии, которую мы пробовали выше, они достигают 0,93 бита на байт.
Трансформатор-XL
Хотя преобразователь представляет собой огромный шаг вперед в моделировании зависимостей на большие расстояния, модели, которые мы видели до сих пор, по-прежнему существенно ограничены размером входных данных.Поскольку размер матрицы скалярного произведения растет квадратично по мере увеличения длины последовательности, это быстро становится узким местом, поскольку мы пытаемся увеличить длину входной последовательности. Transformer-XL — одна из первых успешных моделей трансформаторов, решивших эту проблему.
Во время обучения длинная последовательность текста (более длинная, чем могла бы обработать модель) разбивается на более короткие сегменты. Каждый сегмент обрабатывается последовательно, при этом самовнимание вычисляется по токенам в текущем сегменте и предыдущем сегменте .Градиенты вычисляются только для текущего сегмента, но информация по-прежнему распространяется, когда окно сегмента перемещается по тексту. Теоретически на уровне \ (n \) можно использовать информацию из сегментов \ (n \) назад.
Подобный трюк в обучении RNN называется усеченным обратным распространением во времени. Мы скармливаем модели очень длинную последовательность, но распространяем обратное распространение только по ее части. Первая часть последовательности, для которой не вычисляются градиенты, по-прежнему влияет на значения скрытых состояний в той части, для которой они есть.Чтобы эта работа работала, авторам пришлось отказаться от стандартной схемы кодирования / встраивания позиций. Поскольку кодирование позиции — , абсолютное , оно будет меняться для каждого сегмента и не приведет к последовательному внедрению по всей последовательности. Вместо этого они используют относительную кодировку . Для каждого выходного вектора используется другая последовательность векторов положения, которая обозначает не абсолютное положение, а расстояние до текущего выхода.
Для этого необходимо переместить кодировку позиции в механизм внимания (подробно описанный в статье).Одно из преимуществ состоит в том, что полученный преобразователь, вероятно, будет намного лучше обобщать последовательности невидимой длины.
Редкие трансформаторы
Редкие трансформаторы решают проблему квадратичного использования памяти. Вместо вычисления плотной матрицы весов внимания (которая растет квадратично), они вычисляют самовнимание только для определенных пар входных токенов, в результате получается разреженная матрица внимания только с \ (n \ sqrt {n} \) явные элементы.
Это позволяет создавать модели с очень большими размерами контекста, например, для генеративного моделирования по изображениям, с большими зависимостями между пикселями.Компромисс заключается в том, что структура разреженности не изучена, поэтому путем выбора разреженной матрицы мы отключаем некоторые взаимодействия между входными токенами, которые в противном случае могли бы быть полезны. Однако два модуля, которые не связаны напрямую, могут все еще взаимодействовать на более высоких уровнях трансформатора (аналогично тому, как сверточная сеть создает большее принимающее поле с большим количеством сверточных слоев).
Помимо простого преимущества обучающих трансформаторов с очень большой длиной последовательности, разреженный трансформатор также позволяет очень элегантно спроектировать индуктивное смещение.Мы принимаем наши входные данные как набор единиц (слова, символы, пиксели на изображении, узлы на графике) и указываем через разреженность матрицы внимания, какие единицы мы считаем связанными. 2 \) элементов.При стандартной 32-битной точности и \ (t = 1000 \) пакет из 16 таких матриц занимает около 250 МБ памяти. Поскольку нам нужно как минимум четыре из них на операцию самовнимания (до и после softmax, плюс их градиенты), это ограничивает нас максимум двенадцатью слоями в стандартном графическом процессоре 12 Гб. На практике мы получаем еще меньше, поскольку входы и выходы также занимают много памяти (хотя скалярное произведение преобладает).
И все же модели, описанные в литературе, содержат последовательности длиной более 12000, с 48 слоями, с использованием плотных матриц скалярных произведений.Эти модели, конечно, обучаются на кластерах, но для выполнения одного прямого / обратного прохода по-прежнему требуется один графический процессор. Как уместить такие огромные трансформаторы в 12 ГБ памяти? Есть три основных приема:
- половинная точность
- На современных графических процессорах и на TPU тензорные вычисления могут эффективно выполняться на 16-битных тензорах с плавающей запятой. Это не так просто, как просто установить dtype тензора на
torch.float16. Для некоторых частей сети, например для потерь, требуется 32-битная точность.Но с большей частью этого можно относительно легко справиться с помощью существующих библиотек. Фактически это удваивает вашу эффективную память. - Накопление градиента
- Для большой модели мы можем выполнить прямой / обратный проход только для одного экземпляра. Размер пакета 1 вряд ли приведет к стабильному обучению. К счастью, мы можем выполнить одиночный переход вперед / назад для каждого экземпляра в более крупном пакете и просто суммировать найденные градиенты (это следствие правила многомерной цепочки).Когда мы достигаем конца пакета, мы делаем один шаг градиентного спуска и обнуляем градиент. В Pytorch это особенно просто: вы знаете, что вызов
optimizer.zero_grad ()в вашем цикле обучения кажется таким излишним? Если вы этого не сделаете, новые градиенты просто добавятся к старым. - Градиентная контрольная точка
- Если ваша модель настолько велика, что даже одиночный переход вперед / назад не помещается в памяти, вы можете обменять еще больше вычислений на эффективность памяти.В контрольной точке градиента вы разделяете свою модель на секции. Для каждого раздела вы выполняете отдельный переход вперед / назад для вычисления градиентов, не сохраняя промежуточные значения для остальных. В Pytorch есть специальные утилиты для проверки градиента.
Для получения дополнительной информации о том, как это сделать, см. Это сообщение в блоге.
Заключение
Трансформатор вполне может быть самой простой архитектурой машинного обучения, которая будет доминировать в этой области за десятилетия. Есть веские причины обратить на них внимание, если вы еще этого не сделали.
Во-первых, текущий предел производительности находится исключительно в аппаратном обеспечении . В отличие от сверток или LSTM текущие ограничения того, что они могут делать, полностью определяются тем, насколько велика модель, которую мы можем разместить в памяти графического процессора, и сколько данных мы можем передать через нее за разумный промежуток времени. Я не сомневаюсь, что в конечном итоге мы достигнем точки, когда больше слоев и больше данных больше не помогут, но, похоже, мы еще не достигли этой точки.
Во-вторых, трансформатора чрезвычайно универсальны .До сих пор большие успехи были достигнуты в языковом моделировании, с некоторыми более скромными достижениями в анализе изображений и музыки, но преобразователь имеет уровень универсальности, который еще только предстоит использовать. Базовым трансформатором является комплектная модель . Пока ваши данные представляют собой набор единиц, вы можете применить трансформатор. Все, что вам известно о ваших данных (например, локальная структура), вы можете добавить с помощью встраивания позиций или манипулирования структурой матрицы внимания (делая ее разреженной или маскируя части).
Это особенно полезно при мультимодальном обучении. Мы могли бы легко объединить изображение с подписью в набор пикселей и символов и разработать некоторые умные вложения и структуру разреженности, чтобы помочь модели понять, как объединить и выровнять их. Если мы объединим всю полноту наших знаний о нашей предметной области в реляционную структуру, такую как многомодальный граф знаний (как обсуждается в [3]), можно использовать простые блоки-преобразователи для распространения информации между мультимодальными единицами и согласования их с разреженная структура, обеспечивающая контроль над тем, какие единицы напрямую взаимодействуют.
Пока что трансформеры по-прежнему рассматриваются в первую очередь как языковая модель. Я ожидаю, что со временем мы увидим их применение в других областях не только для повышения производительности, но и для упрощения существующих моделей, а также для того, чтобы позволить практикам более интуитивно контролировать индуктивные искажения своих моделей.
Список литературы
[1] Иллюстрированный трансформер, Джей Алламар.
[2] Аннотированный трансформер, Александр Раш.
[3] Граф знаний как модель данных по умолчанию для обучения на основе гетерогенных знаний Ксандер Вилке, Питер Блум, Виктор де Бур
[4] Методы матричной факторизации для рекомендательных систем Иегуда Корен и др.
Обновления
- 19 октября 2019
- Добавлен раздел о разнице между широким и узким самовниманием. Спасибо Сидни Мело за обнаружение ошибки в исходной реализации.
Понимание условных обозначений в трансформаторах
Трансформаторы можно найти практически везде, от больших электростанций до компактных цепей SMPS. Хотя существует много типов трансформаторов, и их точная работа различается в зависимости от области применения, основные принципы работы трансформатора остаются неизменными.Когда мы изучаем схему с трансформатором внутри, мы могли заметить «точки», похожие на символы, размещенные на одном конце обмоток трансформатора. Эти символы размещаются в соответствии с правилом условного обозначения точек. Но что это? И какой цели это служит?
Что такое Dot Convention?Точечное обозначение — это тип маркировки полярности для обмоток трансформатора , показывающий, какой конец обмотки находится по отношению к другим обмоткам. Он используется для обозначения фазовых соотношений на принципиальных схемах трансформатора и включает в себя размещение точек поверх первичных и вторичных выводов, как показано ниже.
Если точки расположены рядом с верхними концами первичной и вторичной обмоток, как показано ниже, это означает, что полярность мгновенного напряжения на первичной обмотке будет такой же, как и на вторичной обмотке. Это означает, что фазовый сдвиг между первичной и вторичной обмотками будет равен нулю (синфазный) , а направление вторичного тока (Is) и первичного тока (Ip) будет одинаковым.
Однако, если точки расположены в обратном порядке (например,грамм. вверх на первичной, вниз на вторичной или наоборот), как на изображении ниже, это означает, что первичный и вторичный ток и напряжения сдвинуты по фазе на 180 °, а первичный и вторичный токи (IP и IS) будут противоположными по направлению для другого.
Зная это соглашение и полярность трансформатора, инженеры теперь имеют свою судьбу в своих руках и могут решить изменить фазовые соотношения любым способом, который они хотят, изменив, какой конец их цепи подключен к клеммам трансформатора. .Например, для приведенного выше примера с противофазным трансформатором, переключая способ подключения клемм, как показано на изображении ниже, вторичная сторона становится синфазной с первичной.
Почему важна точечная конвенция?При исследовании трансформаторов обычно предполагается (по крайней мере, для резистивных нагрузок), что напряжение и ток находятся в фазе для вторичной и первичной обмоток. Это предположение обычно основано на предположении, что вторичная обмотка и первичная обмотка трансформатора расположены в одном направлении .Соотношение фаз между первичными и вторичными токами и напряжениями зависит от того, как каждая обмотка намотана вокруг сердечника, следовательно, если обмотка намотана вокруг сердечника в том же направлении, как показано ниже; тогда напряжение и ток на обеих сторонах должны быть в фазе.
Однако это предположение не всегда верно, поскольку направление обмоток может быть противоположным (как показано на изображении выше), что будет означать, что если подключение осуществляется к одним и тем же клеммам, то напряжение во вторичной обмотке (VS) будет быть в противофазе, а направление тока (Is) противоположно направлению первичного тока.
Эта потеря фазы и обратная полярность , как бы банально это ни звучало, создают серьезные проблемы в системах защиты, измерения и управления энергосистемы. Например, изменение полярности в обмотке измерительного трансформатора может привести к выходу из строя защитных реле, привести к неточным измерениям мощности и энергии или к отображению отрицательного коэффициента мощности во время измерений. Это также может привести к эффективному короткому замыканию в параллельных обмотках трансформатора и в сигнальных цепях, может привести к неправильной работе усилителей и акустических систем или к отмене сигналов, которые предназначены для добавления.
Поскольку трансформаторы непрозрачны, невозможно узнать, каким образом подключить к ней цепь, чтобы получить синфазное (или не синфазное) напряжение и ток, таким образом, чтобы снизить риски, связанные с подключением обратной полярности и потеря фазы и способ определения полярности обмоток, производители трансформаторов разработали стандарт индикации полярности, который называется; « Dot Convention ».
Буквенно-цифровые таблички на трансформаторахПомимо точечного обозначения, другой способ индикации полярности , используемый в трансформаторах , — это буквенно-цифровые метки , , которые обычно состоят из букв «H» и «X» вместе с индексами, которые представляют полярность обмотки.Провода «1» (h2 и X1) показывают, где обычно размещаются точки маркировки полярности. Типичный трансформатор с буквенно-цифровой этикеткой показан ниже.
.